C++でsplit (3) – utf16版
1.補助関数の作成
次のutf16文字へのポインタを取得する
char16_t* next_c_u16(const char16_t* c) { if (IS_SURROGATE_PAIR(c[0], c[1]) == true) return (char16_t*)c + 2; return (char16_t*)c + 1; }
utf16文字を一文字取り出す
//utf16文字を一文字取り出す void ext_c_u16(char16_t* const dst, const char16_t* src,int* size) { int sz; if (IS_SURROGATE_PAIR(src[0], src[1]) == true) sz = 4; else sz = 2; memcpy(dst, src, sz); dst[sz/2] = char16_t(0); if(size) *size = sz; }
utf16文字を比較する
//utf16文字を比較する bool cmp_c_u16(const char16_t* c1, const char16_t* c2) { int K = bytes_c_u16(c1); int L = bytes_c_u16(c2); if (K != L) return false; bool issame = (memcmp(c1, c2, K) == 0); return issame; }
utf16文字のバイト数を返す関数
//文字のバイト数を取得 int bytes_c_u16(const char16_t* c) { if (IS_SURROGATE_PAIR(c[0], c[1]) == true) return 4; return 2; }
split関数本体
std::vector<std::u16string> split_u16(const char16_t* src, const char16_t* del) { char16_t tmp[10]; std::vector<std::u16string> result; std::u16string tmps; while (*src) { //デリミタを飛ばす const char16_t* p = src; while (cmp_c_u16(src, del) == true && *src != '\0') src = next_c_u16(src); //デリミタに遭遇するまで文字を追加し続ける while (cmp_c_u16(src, del) != true && *src != '\0') { ext_c_u16(tmp, src, nullptr);//一文字取り出す tmps += tmp; src = next_c_u16(src); } if (tmps.size()) { result.push_back(tmps); } tmps.clear(); } return result; }
実験1
int main() { setlocale(LC_ALL, ""); char16_t* u16 = (char16_t*)L"C:\\いろは\\山田\\abc\\"; std::ofstream f(L"c:\\test\\test.txt", std::ios::out | std::ios::binary); std::vector<std::u16string> ret = split_u16(u16, (char16_t*)L"\\"); for (size_t i = 0; i < ret.size(); i++) { wprintf(L"[%s]", (wchar_t*)ret[i].c_str()); } f.close(); return 0; }
結果1
[C:][いろは][山田][abc]
実験2

結果2

余談
サロゲートペアの文字一覧はここから
WordPressで上記文字を入力したところなぜか記事の保存ができなかったので、実験2は画像にしている。
C++でsplit (2) – マルチバイト版,’\’対応
1.補助関数作成
次のマルチバイト文字へのポインタを取得する関数
//次のマルチバイト文字へのポインタを取得 const char* next_c_mb(const char* c) { int L = mblen(c, 10); return c + L; }
マルチバイト文字を一文字取り出す
//マルチバイト文字を一文字取り出す void ngetc(char* const dst,const char* src) { int L = mblen(src, 10); memcpy(dst, src, L); dst[L] = '\0'; }
マルチバイト文字を比較する
//マルチバイト文字を比較する bool nchr_cmp(const char* c1, const char* c2) { int K = mblen(c1, 10); int L = mblen(c2, 10); if (K != L) return false; bool issame = (strncmp(c1, c2, K) == 0); return issame; }
2.split関数本体
std::vector<std::string> split_mb(const char* src, const char* del) { char tmp[10]; std::vector<std::string> result; std::string tmps; while (*src) { //デリミタを飛ばす const char* p = src; while (nchr_cmp(src, del) == true && *src != '\0') src= next_c_mb(src); //デリミタに遭遇するまで文字を追加し続ける while (nchr_cmp(src, del) != true && *src != '\0') { ngetc(tmp, src);//一文字取り出す tmps += tmp; src = next_c_mb(src); } if (tmps.size()) { result.push_back(tmps); } tmps.clear(); } return result; }
実験
setlocale(LC_ALL, ""); std::vector<std::string> ret = split_mb("C:\\日本語表示フォルダ\\test\\contains", "\\"); for (size_t i = 0; i < ret.size(); i++) { printf("[%s]", ret[i].c_str()); }
結果
[C:][日本語表示フォルダ][test][contains]
注意
mblenはlocaleの影響を受けるのでsetlocaleする。
しない場合、’表’が1byteとしてカウントされてしまう。
C++でsplit (1) – strtok版
strtokによる分割プログラム
strtokを使った典型的なsplitの結果をstringのvectorに格納する。
ありきたりだがとりあえず此が一番事故がない。
#include <string.h> #include <vector> //! @brief 文字列分割関数(マルチバイト文字版) //! @param [in] src 対象の文字列 //! @param [in] del 区切り文字を列挙した文字列 //! @return 分割後の文字列 std::vector<std::string> split_mb(const char* src, const char* del) { std::vector<std::string> result; //strtokは元の文字列を書き換えるので //作業用の領域を作って元データをコピーする std::vector<char> vtxt(strlen(src) + 1,'\0'); char *txt = &vtxt[0]; strcpy(txt, src); char* t = strtok(txt, del); if (strlen(t) != 0) { result.push_back(t); } while (t != NULL) { t = strtok(NULL, del); if (t != NULL) { result.push_back(t); } } return result; } //! @brief 文字列分割関数(ワイド文字版) //! @param [in] src 対象の文字列 //! @param [in] del 区切り文字を列挙した文字列 //! @return 分割後の文字列 std::vector<std::wstring> split_wc(const wchar_t* src, const wchar_t* del) { std::vector<std::wstring> result; std::vector<wchar_t> vtxt(wcslen(src) + 1, '\0'); wchar_t* txt = &vtxt[0]; wcscpy(txt, src); wchar_t* t = wcstok(txt, del); if (wcslen(t) != 0) { result.push_back(t); } while (t != nullptr) { t = wcstok(nullptr, del); if (t != nullptr) { result.push_back(t); } } return result; }
結果出力
for (size_t i = 0; i < cret.size(); i++) { printf("[%s]",cret[i].c_str()); }
strtokで生じる問題
実験1
分割文字が連続していても思った通りに分割出来る
std::vector<std::string> cret =
split_mb("hello world characters", " ");
結果
[hello][world][characters]
実験2
此は成功する
std::vector<std::string> cret =
split_mb("C:\\test\\english folder\\contents\\", "\\");
結果
[C:][test][english folder][contents]
実験3
「表示」のように分割文字が入っている場合は、思ったような結果が得られない
std::vector<std::string> cret =
split_mb("C:\\test\\日本語表示フォルダ\\内容\\", "\\");
結果
[C:][test][日本語評[示フォルダ][内容]
C/C++ fgetsで一行読み込む
fgetsで一行取得するサンプルは多数あるのだけれど一行がバッファサイズ超えたらどうするのというサンプルがあまりなかった。というか意味をなさないのだろうけれど。
呼び出し元
int main() { char* txt = new char[1024]; FILE* fp = fopen("test.txt", "r"); bool readable = true; while(readable){ read_1_line(txt, fp);//一行読み込み printf("%s\n", txt); readable = feof(fp) == 0; } getchar(); delete[] txt; return 0; }
一行読み込み関数
関数本体
バッファサイズが小さいので大抵は一行に収まりきらず複数回fgetsが走る。そしてfgetsがnullptrを返すか、読み込んだ文字列の最後が"\n\0"という並びの時だけループを抜ける。
#include <cstring> void read_1_line(char* txt, FILE* fp) { txt[0] = '\0'; const int BUF_SIZE = 10;//バッファサイズが小さい char buffer[BUF_SIZE]; while(fgets(buffer, BUF_SIZE, fp) ){ strcat(txt, buffer); char* p = strchr(txt, '\n');//改行の削除 if (p) { *p = '\0'; break; } } }
fgetsの挙動と改行の削除
fgetsは改行までを一行と見なして読み込む。大抵は改行が最後に入るのだが入らないこともあるのでこの方法をとる。
(参考)FIO36-C. fgets() が改行文字を読み取ると仮定しない
バッファサイズが10,読み込み文字がそれぞれ以下の時のfgetsで読み込まれる内容。
| ファイル内の一行の文字 | 一回目 | 二回目 | コメント |
| 01234567 | 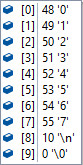 | -- | 一回で読み込める。 最後に改行 末尾は'\0' |
| 012345678 | 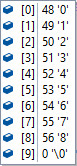 | 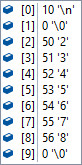 | 二回にわたって読み込む。 一回目に改行は入らない。 二回目は、一回目で読めなかった'\n'だけが読み込まれる 末尾は [1] 0 '\0' となりnull終端 |
| 0123456789 | | 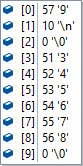 | 二回にわたって読み込む。 一回目に改行は入らない。 二回目は、一回目で読めなかった'9' '\n' 末尾は [2] 0 '\0' となりnull終端 |
C++のstring型に結合するように変更
このままでは結局引数txtの要素数に依存してしまうので、結果をどんどんstring型変数へ結合していく。
std::string read_1_line(FILE* fp) { std::string str; const int BUF_SIZE = 10; char buffer[BUF_SIZE]; while (fgets(buffer, BUF_SIZE, fp)) { char* p = strchr(buffer, '\n'); if (p) { *p = '\0'; } str += buffer; if (p)break; } return str;//コピーコスト?知らん。 }
もっともこれをやりだすとそもそもfgetsを使う必要云々という議論に発展する気がする。でもfstreamは嫌いだ。
ファイル名を自然ソートする(StrCmpLogicalW)
手順
①ファイル名を取得(wchar_t で )
②自然ソート
③必要ならcharへ変換
というステップで行います。
②StrCmpLogicalWで自然ソート (核心)
この記事の核心自然ソートです。前提として、ファイル名は
std::vector<std::wstring>
で管理されています。
StrCmpLogicalWを使う時はShlwapi.hをインクルード、shlwapi.libをリンクします。
#include <Shlwapi.h> #pragma comment(lib,"shlwapi.lib")
void sort_file_names(std::vector<std::wstring>& fnlist) { std::sort( fnlist.begin(), fnlist.end(),
//ラムダ関数 [](const std::wstring& n1, const std::wstring& n2) { return StrCmpLogicalW(n1.c_str(), n2.c_str()) < 0; } ); }
①ファイル一覧取得
ファイル名一覧を取得。StrcmpLogicalWがワイド文字専用なので、ファイル一覧の段階からワイド文字で取得します。
https://suzulang.com/win32api-get-file-list/
③必要ならcharへ変換
Win32apiでファイル一覧取得
取得用関数(_UNICODE指定時)
std::vector<std::wstring> getfiles(std::wstring path) { HANDLE hFind; WIN32_FIND_DATA win32fd; if (path.back() != L'\\') {//最後を\で終了するようにする path += L'\\'; } path += L"*.*";//ファイル一覧取得時のワイルドカード
//ここに結果を保存 std::vector<std::wstring> files_ws; hFind = FindFirstFile(path.c_str(), &win32fd); if (hFind == INVALID_HANDLE_VALUE) { return files_ws; //一覧が取得できそうにないなら終了 } do { if (win32fd.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY) {
//ディレクトリの時は win32fd.cFileName にディレクトリ名が入っている
//ここで再起などするとさらに深い階層を得られる } else { //ファイル名登録 files_ws.push_back(win32fd.cFileName); } } while (FindNextFile(hFind, &win32fd)); FindClose(hFind); return files_ws; }
各関数・および構造体は、ワイド文字用とマルチバイト文字用で分かれている
| tchar用 | マルチバイト文字用 | ワイド文字用 |
| WIN32_FIND_DATA | WIN32_FIND_DATAA | WIN32_FIND_DATAW |
| FindFirstFile | FindFirstFileA | FindFirstFileW |
| FindNextFile | FindNextFileA | FindNextFileW |
wchar_t* と char* の相互変換
プログラム
色々とやりようはあるしそこらじゅうに転がってるんですがとりあえず自分が納得するものを作ります。
std::wstring towstring(const char* c) { std::wstring tmps; if (c == nullptr) return tmps; size_t sz = strlen(c); tmps.reserve(sz);//メモリを確保し、newが走りすぎないようにする const size_t CNT_MAX = 50; char tmpc[CNT_MAX]; wchar_t tmpw[CNT_MAX]; const char* p = c; assert(p); while (*p != '\0') { int L = mblen(p, CNT_MAX);//pが指し示すマルチバイト文字のバイト数を取得 if (L <= 0) break; strncpy(tmpc, p, L);//tmpcにその一文字をコピーする tmpc[L] = '\0';
//multi byte string to wide char string mbstowcs(tmpw, tmpc, CNT_MAX);//tmpcの終端を0にしてあるので人文字だけ変換する tmps += tmpw; p += L; } return tmps; } std::string tostring(const wchar_t* c) { std::string tmps; if (c == nullptr) return tmps; size_t sz = wcslen(c); tmps.reserve(sz*2);//メモリを確保し、newが走りすぎないようにする const size_t CNT_MAX = 50; char tmpc[CNT_MAX]; wchar_t tmpw[CNT_MAX]; const wchar_t* p = c; while (*p) {
//サロゲートペアなら2文字分、違うなら1文字分だけtmpwに確保 if (IS_HIGH_SURROGATE(*p) == true) { wcsncpy(tmpw, p, 2); tmpw[2] = L'\0'; p += 2; } else { wcsncpy(tmpw, p, 1); tmpw[1] = L'\0'; p += 1; } wcstombs(tmpc, tmpw, CNT_MAX);//tmpwの内容を変換してtmpcに代入 tmps += tmpc; } return tmps; }
使う時はsetlocaleが必要です。
setlocale(LC_ALL, "");//必要 const char *c = "こんにちは"; std::wstring s = towstring(c);
IS_HIGH_SURROGATE
ここで、 IS_HIGH_SURROGATEはWindowsのマクロです。
IS_HIGH_SURROGATE macro (winnls.h) | Microsoft Docs
定義は、WinNls.hの中で、
#define IS_HIGH_SURROGATE(wch) (((wch) >= HIGH_SURROGATE_START) && ((wch) <= HIGH_SURROGATE_END))
#define IS_LOW_SURROGATE(wch) (((wch) >= LOW_SURROGATE_START) && ((wch) <= LOW_SURROGATE_END))
#define IS_SURROGATE_PAIR(hs, ls) (IS_HIGH_SURROGATE(hs) && IS_LOW_SURROGATE(ls))
こんな感じで定義されています。 なお、
#define HIGH_SURROGATE_START 0xd800 #define HIGH_SURROGATE_END 0xdbff #define LOW_SURROGATE_START 0xdc00 #define LOW_SURROGATE_END 0xdfff
mblen
用途:
stringが指す先のマルチバイト文字のバイト数を返す。
例えば、 'a' なら1 , 'あ'なら2
使い方
他所を参照(手抜き)
mblen | Programming Place Plus C言語編 標準ライブラリのリファレンス
注意
スレッドセーフではない。スレッドセーフであってほしいときはmbrlenを使う
mbstowcs
用途
マルチバイト文字列をワイド文字列に変換する。mbs to wcs。
使い方
他所を参照
mbstowcs | Programming Place Plus C言語編 標準ライブラリのリファレンス
wcstombs
ワイド 文字列を マルチバイト 文字列に変換する。 wcs to mbs。
使い方
Blender 2.8でCyclesを使う
難しいことではないんですがUIが変わったせいで見つけるのが大変
1.レンダラの選択
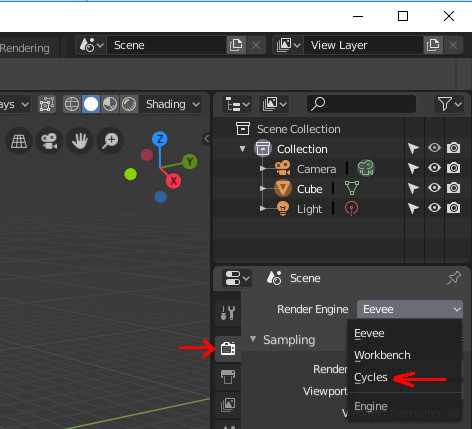
[Render]→[RenderEngine]→Cyclesを設定
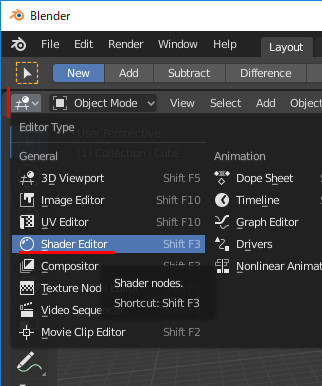
2.Node Editorを表示
名前がNode EditorからShader Editorに変更されました。
デフォルトで"Principled BSDF"が適用されています。
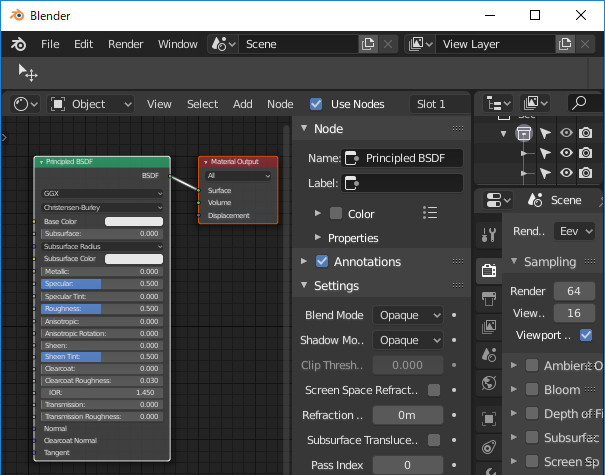
[Shift+A]のショートカットキーは健在なので、ノードを追加出来ます。
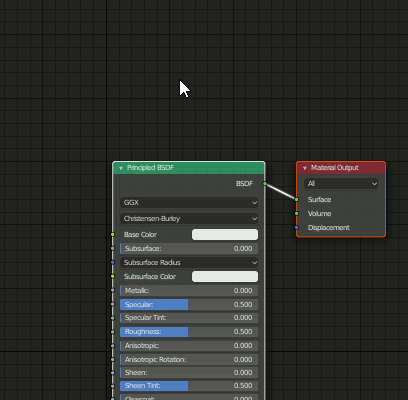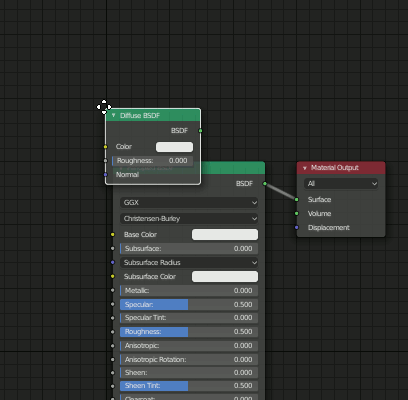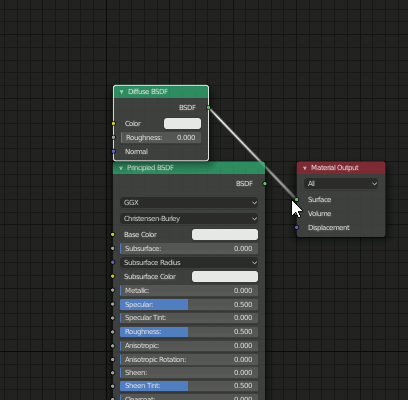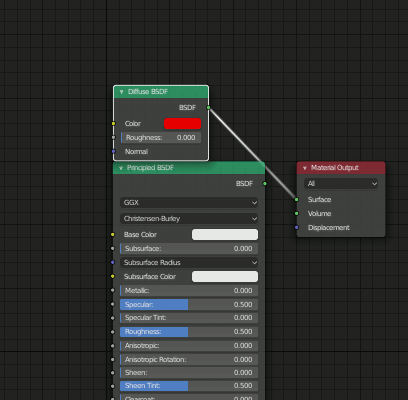
3.各種設定
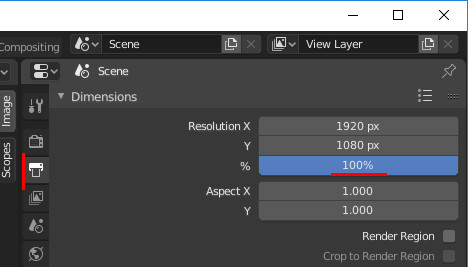
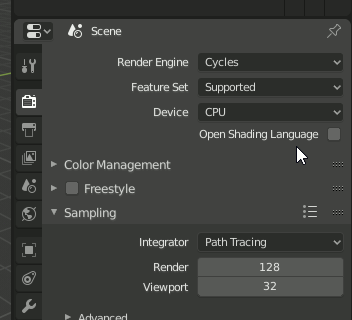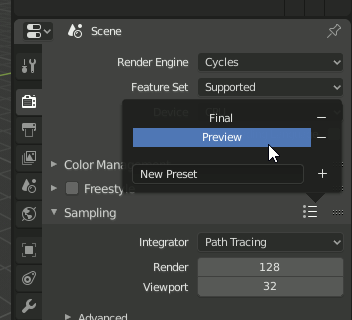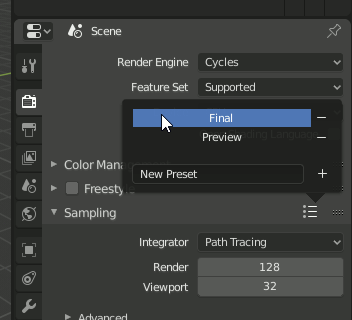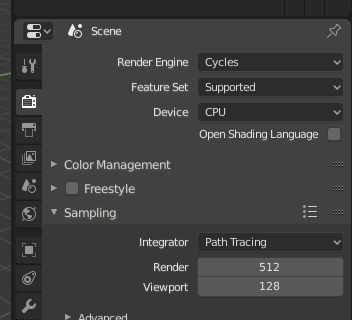
デフォルトでResolutionが100%になっているのでマシンスペックの低い人は注意してください。
SamplingのFinal↔Previewを変更するのは[Render]→[Sampling]のアイコンをクリックします。
注意 バグなのか仕様なのかはわからないけれど"Preview"とか"Final"をクリックした瞬間変わらないで、マウスを選択肢の外に出して一覧が消えた後で変わります。
4.レンダリングの実行
実行は今までと同じようにRenderメニューからRender Imageを選択します。
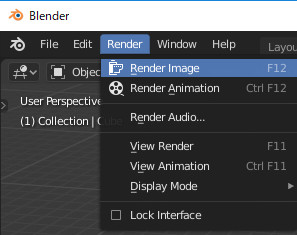
レンダリングを開始するとレンダリング用のウィンドウが出ます。このウィンドウを消すとレンダリングが中断出来ます。
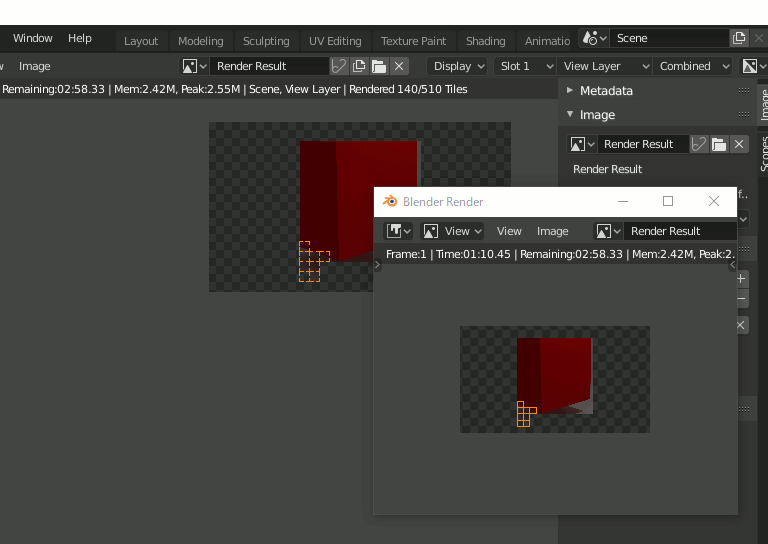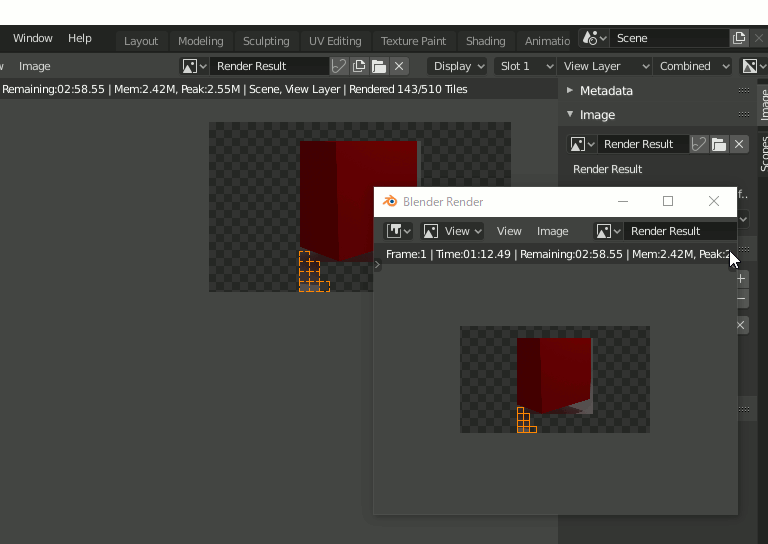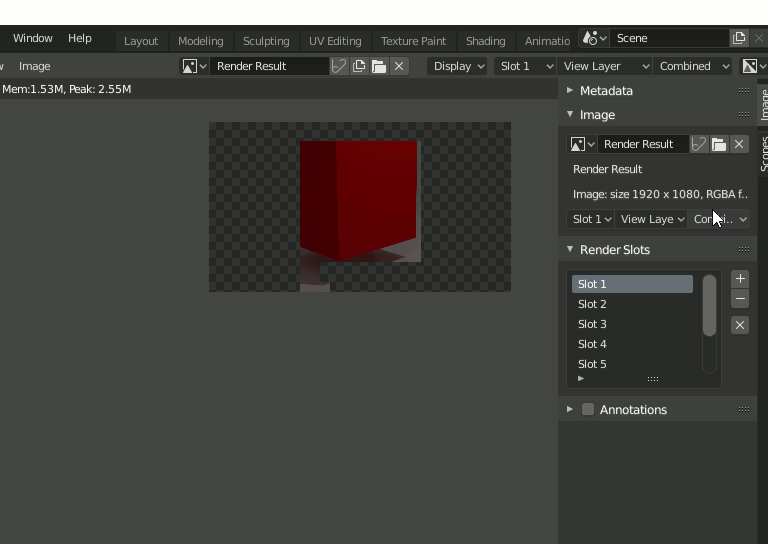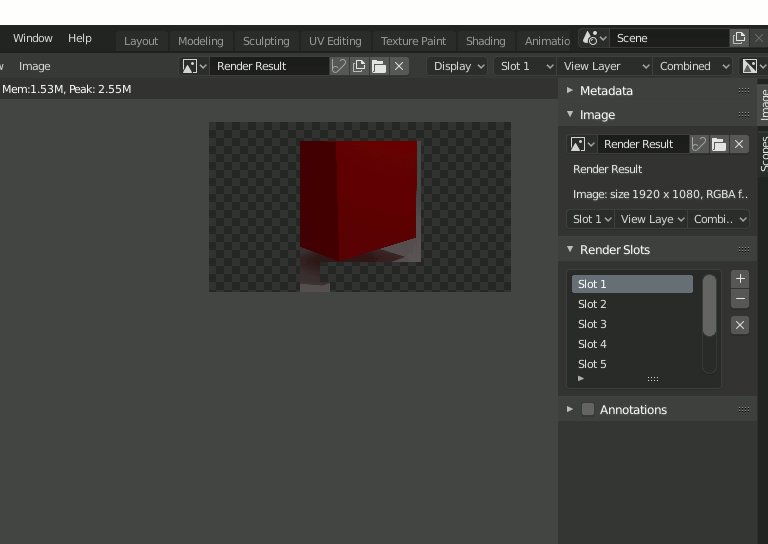
結果の確認はRenderingタブから。

保存は[Shift+S]でできます。
わからなくなったら[F3]を押してSaveとかそれっぽい単語を打ち込むと機能が出てくるかもしれません。
Blender 2.8β Layerが消えた
Blender 2.8からレイヤー機能がなくなり、Collection機能を使うことになります。

画面右上にあるアイコンからもCollectionの表示を切り替えられます

ショートカットキーは [Ctrl+H]です。
全てのCollectionを表示するショートカットキーは[Alt+H]です。ただし、私がやったときはアウトライナーウィンドウにマウスが置かれていないと動きませんでした。仕様かバグかはよくわかりません。

Blender 2.8βでUIが大きく変わった
調べたところ、旧UIに戻す方法はないそうです。
最も混乱するところは、マウスの左ボタンでオブジェクトを選択します。
そしてショートカットキーがだいぶ変わっています。新たな機能、なくなった機能もあり気持ちはわかりますが覚え直しです。
あと全体的にレイアウトというより思想がだいぶ変わってるので違いを挙げるのは大変です(多すぎる)
Node Editor が Shader Editorに代わっている
続く・・・