Ubuntu 20でOpen3Dをソースからビルド
まずgitをインストール。
そしてOpen3Dをダウンロード。git cloneをするとレポジトリをダウンロードしてくれる。嫌ならブラウザから行ってDownload Zipとかでもいい。
ダウンロードした~/develop/Open3 へ入り、util/ ディレクトリにあるinstall_deps_ubuntu.sh スクリプトを実行。これによりOpen3Dが依存しているものが導入されるらしい。
インストール先のディレクトリ作成
ビルドのためのディレクトリ作成
ビルドディレクトリへ行き、cmake をOpen3D/ に対して走らせる。この時、CMAKE_INSTALL_PREFIXに上で作成したインストールディレクトリを指定しておく
make , 及び make install
サンプルコードとビルド
サンプルコード
#include <open3d/Open3D.h> #include <open3d/geometry/PointCloud.h> #include <iostream> #include <memory> int main(){ std::shared_ptr<open3d::geometry::PointCloud> pc = std::make_shared<open3d::geometry::PointCloud>(); pc->points_.push_back(Eigen::Vector3d(0.0, 0.1,0.7)); pc->points_.push_back(Eigen::Vector3d(1.0, 0.0,0.0)); pc->points_.push_back(Eigen::Vector3d(0.5,-0.3,0.1)); open3d::io::WritePointCloudToPLY("points.ply",*pc,true); std::cout << pc->points_.size() << std::endl; }
ビルド
~/develop/Open3D_install/lib 以下の全てのlibOpen3D*.aをリンクしている。
filesystemを使うためlibstdc++fs.a、OpenMPのために -fopenmp を指定。
余談
一週間近く掛けた気がするが、実はcmakeのビルドで失敗していただけでそこがちゃんどできればOpen3Dのほうは殆ど何も迷うことがなかった。
UbuntuでCMakeをビルドする
諸事情によりUbuntuでCMakeする事になったのだが、apt install cmakeで入れたのではバージョンが足りなかったのでCMakeをソースからビルドする。
10年近くまともにLinuxを触っていなかったので結構苦労した。
必須ツールをダウンロード・インストール
まず以下が必要。
libssl-devはOpenSSLのヘッダなどを使えるようにする物で、CMakeのビルドに必須ではないのだが、OpenSSLなしでビルドすると実際に使うときに苦労するので絶対に入れた方がいい。
ソースをダウンロード
1.作業用ディレクトリを作成
2.CMakeのソースコードをダウンロード
URLは: https://cmake.org/download/
から、Unix/Linux Source (has \n line feeds) cmake-3.22.1.tar.gz をダウンロードするのだがここはlinuxらしくwgetを使うことにする。
以下で該当ファイルを~/developディレクトリにダウンロードする。
3.tarを展開
~/developへ展開する。
ビルド
1.cmakeのソースコードを展開したディレクトリへ移動
2.bootstrap , make , make install
注意
OpenSSLを入れなかった場合、./bootstrap中に以下が出る。
Could not find OpenSSL. Install an OpenSSL development package or
configure CMake with -DCMAKE_USE_OPENSSL=OFF to build without OpenSSL.
もしOpenSSLを使わないと断言できるなら、オプション付きで./bootstrapすれば無効化できる
Twisting Crystals in Blender のチュートリアルを試す(4)
これで最後。
最後のほうは色々試しているのでざっくり纏める。
まず中央部分と周囲の部分を分割し、それぞれに異なるマテリアルを割り当てる。


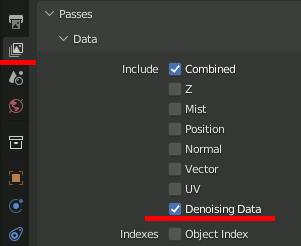
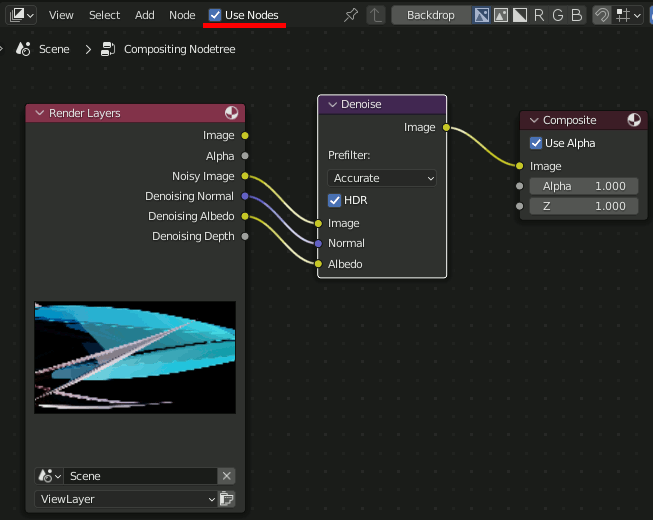
以下、レンダリング設定
Twisting Crystals in Blender のチュートリアルを試す(3)
光源設定
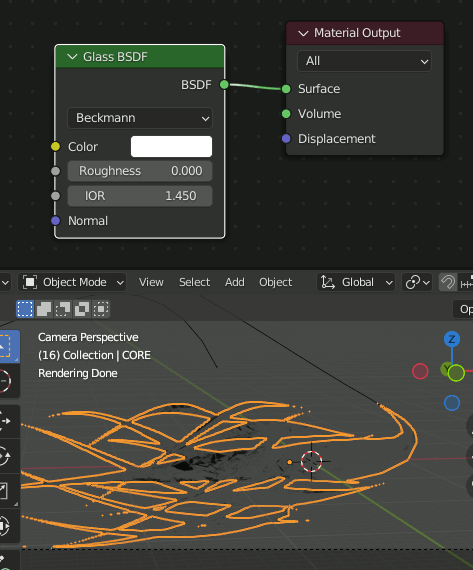
最初に対象物をGlassにしておく。
Planeを追加して
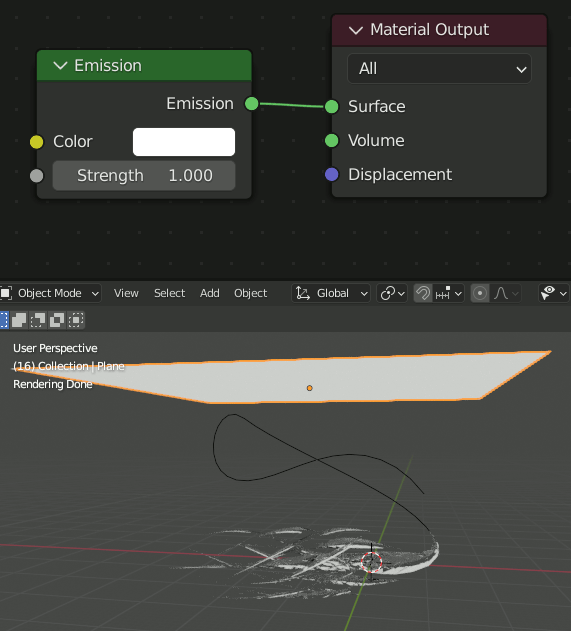
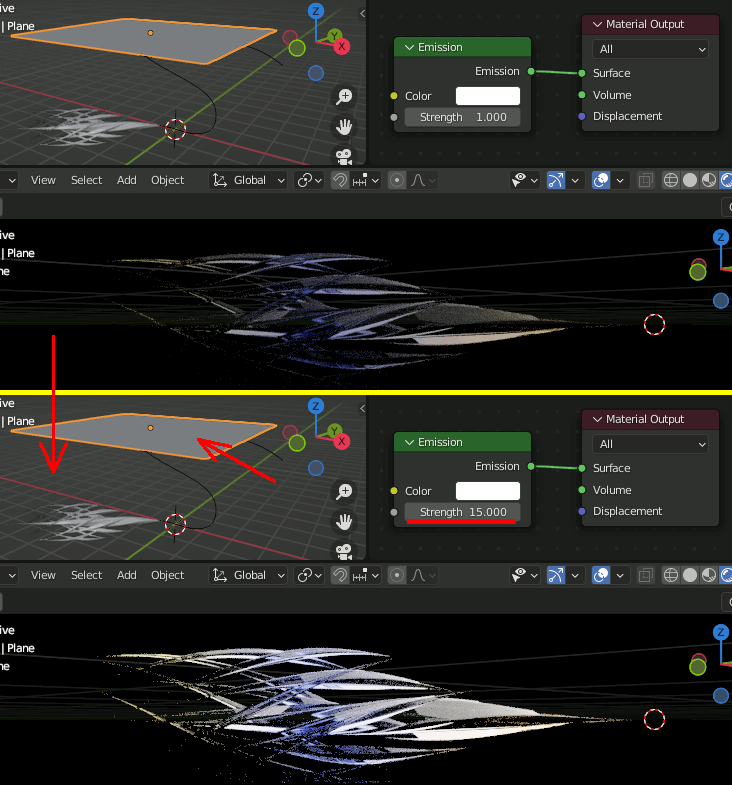
そのままだと背景が灰色(全方位から光が入る)なので、黒(光源以外の光は存在しない)にする。

光源にしているPlaneをカメラで撮影されないように、Ray VisibilityのCameraとShadowを消す。
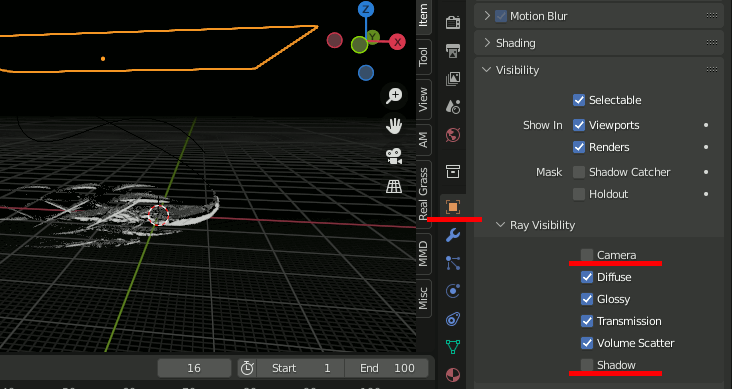
上下両方から光を照らす。

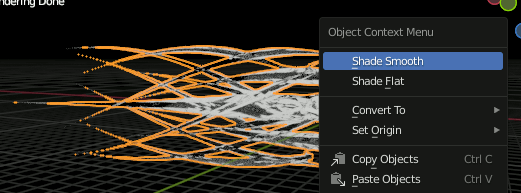
Subdivisionの設定。

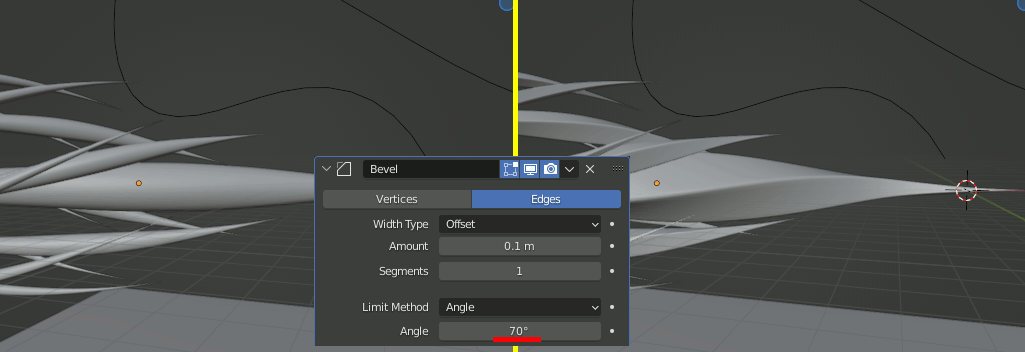
カーブをなめらかにする。

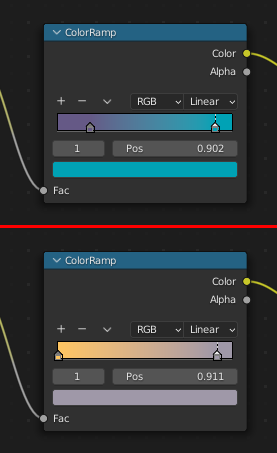
グラスの色をColorRampで着色。

Twisting Crystals in Blender のチュートリアルを試す(2)
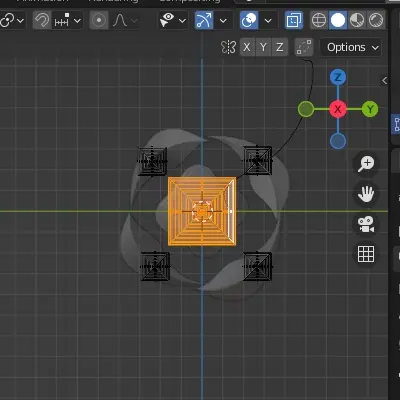
Editモードで[Shift+D]で複製し、四隅に配置する。

やはりEditモードでオリジナルのメッシュだけを拡大。

四隅のメッシュだけを選択し45度回転する。現在中央のメッシュが洗濯されているのでCtrl+iで反転して洗濯できる。
続いてそれを[Shift+D]で複製し、拡大、回転。
拡大の際、[Shift+X]を押してY,Z平面でだけ拡大を行う。
続いて変換の基準をIndivisual Originsに設定して今度は縮小。[Shift+X]でX軸を固定することで細くなる。
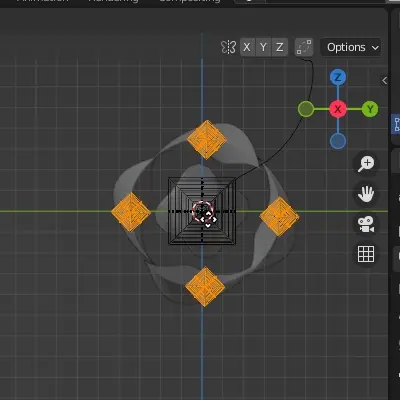
細いメッシュを複製し、Median Pointに戻して回転。
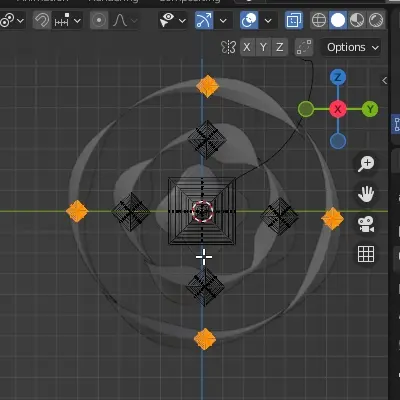
Lキーを押すとマウス付近のメッシュを固まり単位で選択できる。
これで一番外側の細いメッシュを選択し、後ろへずらす。
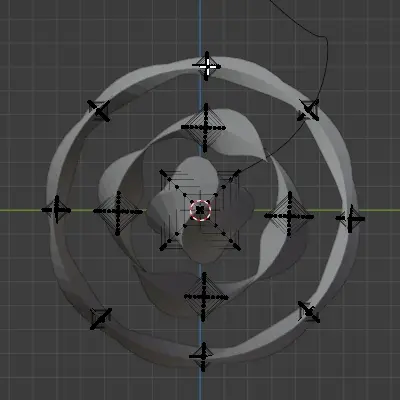
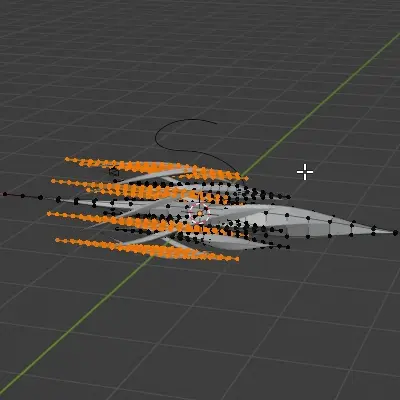
操作方法などを省くと以下のように設定する。
Curveはオブジェクトが置くに飛んでいくように修正し、そう見えるようにカメラを設置する。
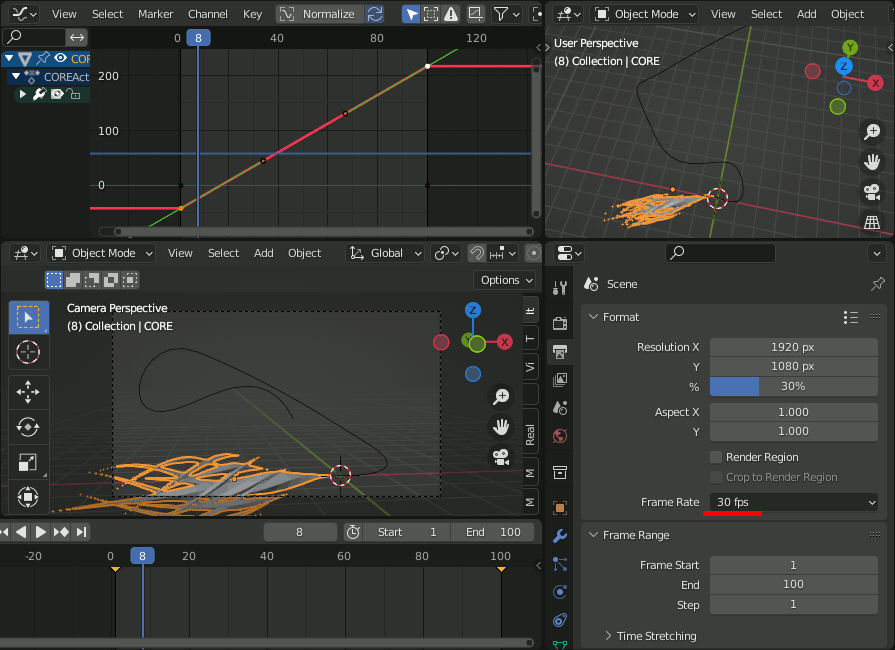
アニメーションを設定し、Graph Editorで[v]を押してvectorに変換。
Frame Rate を30に設定。
Twisting Crystals in Blender のチュートリアルを試す(1)
まず、レンダラをCyclesにする
CubeのTwist
次にデフォルトのCubeをEditモードでX方向に約6倍する。動画内では適当に伸ばしている。

さらにCtrl+Rでループカットを行い、20分割する。動画内では分割数は割と適当に指定している。
加えて、SimpleDeformモディファイアを追加し、 TwistにAngle:-175を指定する。
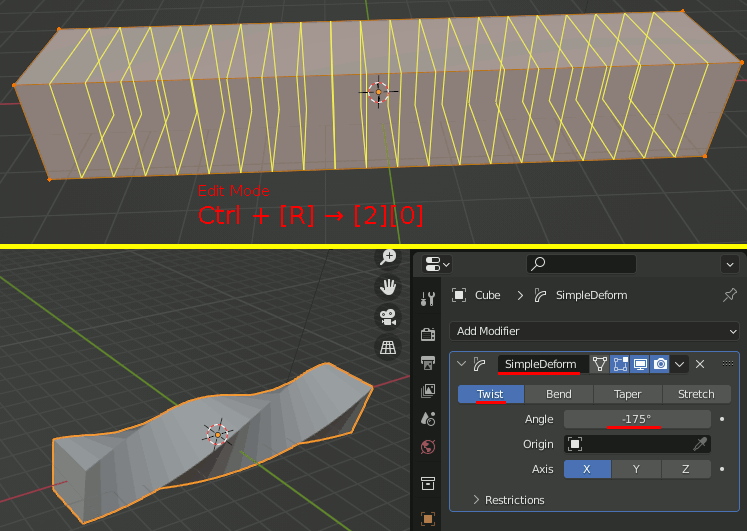
注意 Angle は最終的には-256に設定
ここでCubeの名前をCOREに変更し、必要であればカメラやライトを削除しておく

Curve
Bezierカーブを追加。物体の移動する経路を作る


X,Yの移動をロックするとGキーだけで経路上を移動できるようになる。
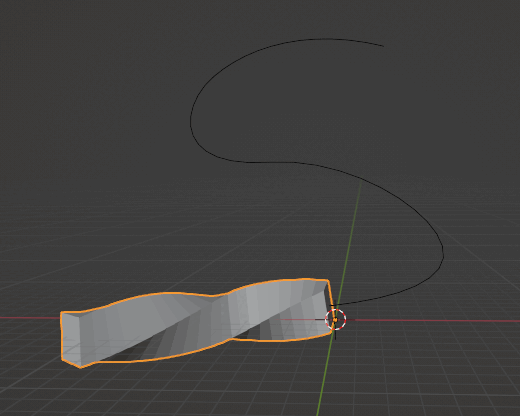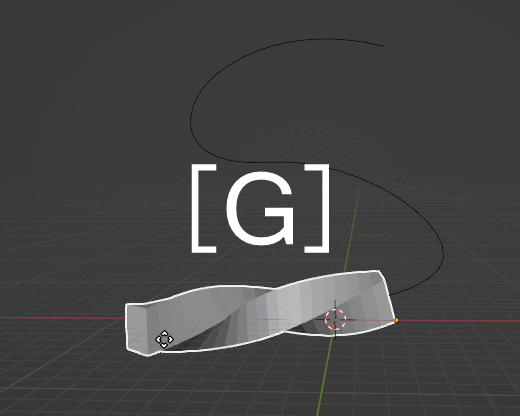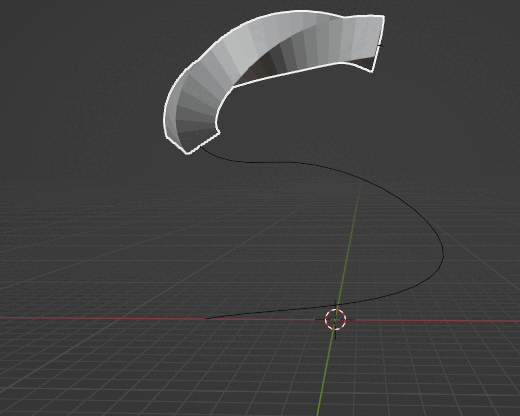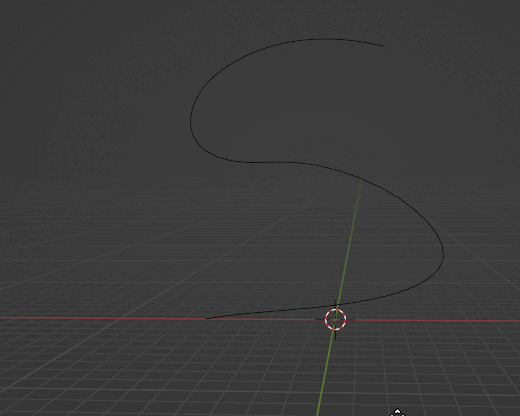
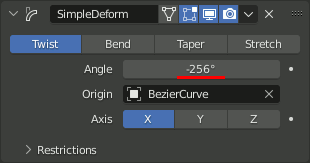
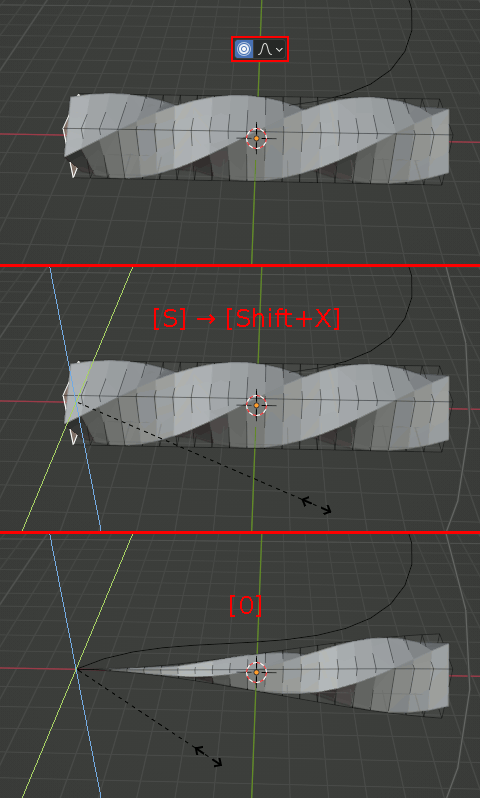
SimpleDeformモディファイアを追加し、OriginをBezierCurveに設定。


Proportional Editingで形状を整える。

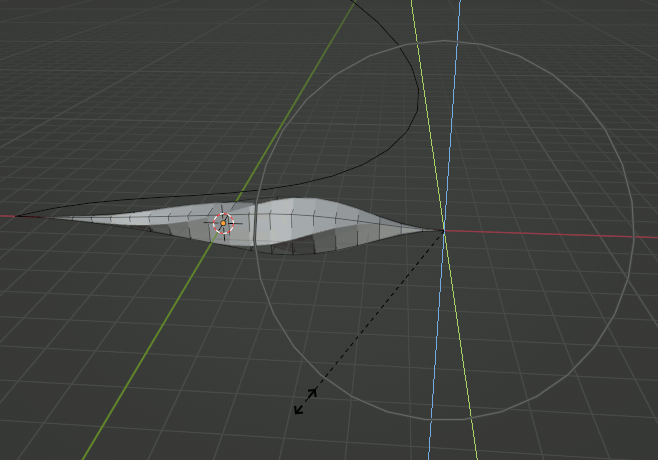
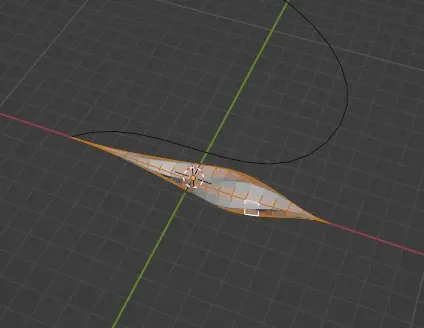
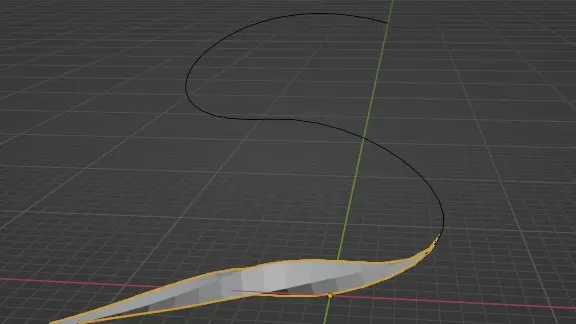
続く
HTMLの見出しに1.1.等の連番を付けるCSS
<h1><h2>の見出しに、1. や1.1. といった見出し番号を付ける。
概要
counter-reset で見出しの番号を初期化する
counter-increment で見出しの番号を進める
content , counter で見出しの表示方法を指定する
見出し連番の例

HTML
<html> <head> <link rel="stylesheet" href="style.css"> </head> <body> <h1>東京都</h1> <h2>港区</h2> <h3>浜松町</h3> <h3>芝浦</h3> <h3>六本木</h3> <h2>中央区</h2> <h3>月島</h3> <h3>日本橋</h3> <h2>北区</h2> <h3>浮間</h3> <h3>東十条</h3> <h1>北海道</h1> <h2>札幌市</h2> <h2>赤平市</h2> <h2>沙流郡</h2> <h1>京都府</h1> <h2>木津川市</h2> <h3>市坂</h3> <h3>加茂町</h3> <h3>吐師</h3> <h2>福知山市</h2> <h2>竹野郡</h2> <h3>網野町</h3> <h3>丹後町</h3> <h3>弥栄町</h3> </body> </html>
CSS (style.css)
body { /* H1のカウンタをリセット */ counter-reset: counter_H1; } /********************************/ h1::before { /* H1の表示方式の設定 */ content: counter(counter_H1) " "; /* H1のカウンタを進める */ counter-increment: counter_H1; } h1{ /* H2のカウンタをリセット */ /* H1 が出てきたときは、H2は1から始まるのでリセットする*/ counter-reset: counter_H2; /* 表示用 */ color:red; padding-left:0px; } /********************************/ h2::before{ /* H2の表示方式の設定 */ content: counter(counter_H1) "-" counter(counter_H2) " "; /* H2のカウンタを進める */ counter-increment: counter_H2; } h2{ /* H3のカウンタをリセット */
/* H2が出てきたときは、H3は1から始まるのでリセットする*/
counter-reset: counter_H3; /* 表示用 */ color:green; padding-left:30px; } /********************************/ h3::before{ /* H3 の表示方式の設定 */ content: counter(counter_H1) "-" counter(counter_H2) "-" counter(counter_H3) " "; /* H3のカウンタを進める */ counter-increment: counter_H3; } h3{ /* 表示用 */ color:blue; padding-left:60px; }
HarfBuzzでFreeType2のレイアウトを調整(2)ラテン系文字とか絵文字
前回作ったプログラムでラテン系の文字や絵文字を描いてみる。
アルファベットの上にaccentがついているもの

int main() { FT_Library library; FT_Error error; error = FT_Init_FreeType(&library); if (error) return -1; ///////////////////////////////////////////// FT_Face* face_jp = my_LoadFonts(library, "C:\\Windows\\Fonts\\Times.ttf"); //////////////////////// hb_font_t* hbfont; hb_buffer_t* hbbuf; //////////////////////// std::u32string text = U"àbâáăã"; //////////////////////// hbbuf = hb_buffer_create(); hb_buffer_add_utf32(hbbuf, (const std::uint32_t*)text.data(), -1, 0, -1); hb_buffer_set_direction(hbbuf, HB_DIRECTION_LTR); hb_buffer_set_script(hbbuf, HB_SCRIPT_LATIN); hb_buffer_set_language(hbbuf, hb_language_from_string("en", -1)); //////////////////////// hbfont = hb_ft_font_create(*face_jp, nullptr); hb_shape(hbfont, hbbuf, NULL, 0); //////////////////////// my_FaceDraw(hbbuf, face_jp); //////////////////////// hb_buffer_destroy(hbbuf); hb_font_destroy(hbfont); //////////////////////// FT_Done_Face(*face_jp); pbmP1_Write("C:\\test\\freetypetest_mgl.pbm", imageWidth, imageHeight, &image[0]); ///////////////////////////////////////////// // FreeType2の解放 FT_Done_FreeType(library); }
絵文字

int main() { FT_Library library; FT_Error error; error = FT_Init_FreeType(&library); if (error) return -1; ///////////////////////////////////////////// FT_Face* face_jp = my_LoadFonts(library, "C:\\Windows\\Fonts\\seguiemj.ttf"); //////////////////////// hb_font_t* hbfont; hb_buffer_t* hbbuf; //////////////////////// std::u32string text = U"👨👨👧👦";//FreeType2だけだと5つの絵文字になる //////////////////////// hbbuf = hb_buffer_create(); hb_buffer_add_utf32(hbbuf, (const std::uint32_t*)text.data(), -1, 0, -1); hb_buffer_set_direction(hbbuf, HB_DIRECTION_LTR); hb_buffer_set_script(hbbuf, HB_SCRIPT_LATIN);//一応LATIN指定しておく hb_buffer_set_language(hbbuf, hb_language_from_string("en", -1));//一応en指定しておく //////////////////////// hbfont = hb_ft_font_create(*face_jp, nullptr); hb_shape(hbfont, hbbuf, NULL, 0); //////////////////////// my_FaceDraw(hbbuf, face_jp); //////////////////////// hb_buffer_destroy(hbbuf); hb_font_destroy(hbfont); //////////////////////// FT_Done_Face(*face_jp); pbmP1_Write("C:\\test\\freetypetest_mge.pbm", imageWidth, imageHeight, &image[0]); ///////////////////////////////////////////// // FreeType2の解放 FT_Done_FreeType(library); }
HarfBuzzでFreeType2のレイアウトを調整(1)
HarfBuzzの目的
あという文字に゛という結合文字がついている場合、理想的にはあ゙と表示される。
ところがFreeTyp2だけでラスタライズすると、以下のようになる。

HarfBuzzを使うと、これを以下のように美しくラスタライズできる。

FreeType2だけの場合
まず比較のためにFreeType2だけでラスタライズするプログラムを書く。
#include <string> #include <array> #include <ft2build.h> #include FT_FREETYPE_H #pragma warning(disable:4996) #if _DEBUG #pragma comment(lib,"freetyped.lib") #else #pragma comment(lib,"freetype.lib") #endif ////////////////////////// // 書き込み先画像 const int imageWidth = 300; const int imageHeight = 150; std::array<unsigned char, imageWidth* imageHeight> image; ////////////////////////// //! @brief imageへの書き込み時のピクセル計算 inline int pixel_pos(const int x, const int y) { return y * imageWidth + x; } //! @brief imageへbmpの内容を書き込む //! @param [in] bmp 文字画像 //! @param [in] startx image画像内の書き込み開始位置 //! @param [in] starty image画像内の書き込み開始位置 void draw(const FT_Bitmap& bmp, int startx, int starty); //! @brief PBM(1byte,テキスト)を書き込む //! @param [in] fname ファイル名 //! @param [in] width 画像の幅 //! @param [in] height 画像の高さ //! @param [in] p 画像のメモリへのアドレス //! @details 1画素1Byteのメモリを渡すと、0,1テキストでファイル名fnameで書き込む void pbmP1_Write(const char* const fname, const int width, const int height, const unsigned char* const p); int main() { FT_Library library; // handle to library FT_Error error; error = FT_Init_FreeType(&library); if (error) return -1; FT_Face face; // handle to face object // フォントファイル読み込み error = FT_New_Face( library, "C:\\Windows\\Fonts\\msgothic.ttc", 0, &face ); //std::u32string text = U"あいう"; // ① std::u32string text = U"あ゙いう"; // ② //文字コード指定 error = FT_Select_Charmap(face,FT_ENCODING_UNICODE); if (error == FT_Err_Unknown_File_Format) return -1; else if (error) return -1; //文字サイズをピクセルで指定 FT_Set_Pixel_Sizes(face,0,64); int pen_x = 0; int pen_y = 0; for (size_t k = 0; k < text.size(); k++) { // 文字の取得 FT_ULong character = text[k]; FT_UInt char_index = FT_Get_Char_Index(face, character); // グリフ(字の形状)読込 error = FT_Load_Glyph(face, char_index, FT_LOAD_RENDER); if (error) return -1; // ignore errors // 文字を画像化 FT_Render_Glyph(face->glyph, FT_RENDER_MODE_NORMAL); // 画像書き込み draw( face->glyph->bitmap, pen_x + face->glyph->bitmap_left, pen_y - face->glyph->bitmap_top + 100 ); // 描画位置を更新 pen_x += face->glyph->advance.x >> 6; pen_y += face->glyph->advance.y >> 6; } // ファイル書き込み pbmP1_Write("C:\\test\\freetypetest.pbm",imageWidth,imageHeight,&image[0]); // FreeType2の解放 FT_Done_Face(face); FT_Done_FreeType(library); }
//! @brief imageへbmpの内容を書き込む //! @param [in] bmp 文字画像 //! @param [in] startx image画像内の書き込み開始位置 //! @param [in] starty image画像内の書き込み開始位置 void draw(const FT_Bitmap& bmp, int startx, int starty) { int Width = bmp.width; int Height = bmp.rows; for (size_t y = 0; y < Height; y++) { for (size_t x = 0; x < Width; x++) { int xx = startx + x; int yy = starty + y; if (xx < 0)continue; if (yy < 0)continue; if (xx > imageWidth - 1)continue; if (yy > imageHeight - 1)continue; #if 0 //枠書き込み if (x == 0 || y == 0 || y == Height - 1 || x == Width - 1) { image[pixel_pos(xx, yy)] = 1; } #endif if (bmp.buffer[y * Width + x]) { image[pixel_pos(xx, yy)] = 1; } } } }
//! @brief PBM(1byte,テキスト)を書き込む //! @param [in] fname ファイル名 //! @param [in] width 画像の幅 //! @param [in] height 画像の高さ //! @param [in] p 画像のメモリへのアドレス //! @details 1画素1Byteのメモリを渡すと、0,1テキストでファイル名fnameで書き込む void pbmP1_Write(const char* const fname, const int width, const int height, const unsigned char* const p) { // PPM ASCII FILE* fp = fopen(fname, "wb"); fprintf(fp, "P1\n%d\n%d\n", width, height); size_t k = 0; for (size_t i = 0; i < (size_t)height; i++) { for (size_t j = 0; j < (size_t)width; j++) { fprintf(fp, "%d ", p[k] ? 0 : 1); k++; } fprintf(fp, "\n"); } fclose(fp); }
HarfBuzz + FreeType2
#include <string> #include <array> #include <ft2build.h> #include FT_FREETYPE_H #include <hb.h> #include <hb-ft.h> #pragma warning(disable:4996) #ifdef _DEBUG #pragma comment(lib,"freetyped.lib") #pragma comment(lib,"harfbuzzd.lib") #else #pragma comment(lib,"freetype.lib") #pragma comment(lib,"harfbuzz.lib") #endif const int imageWidth = 300; const int imageHeight = 150; std::array<unsigned char, imageWidth* imageHeight> image; //! @brief imageへの書き込み時のピクセル計算 int pixel_pos(const int x, const int y) { return y * imageWidth + x; } //! @brief imageへbmpの内容を書き込む //! @param [in] bmp 文字画像 //! @param [in] startx image画像内の書き込み開始位置 //! @param [in] starty image画像内の書き込み開始位置 void draw(const FT_Bitmap& bmp, int startx, int starty); //! @brief PBM(1byte,テキスト)を書き込む //! @param [in] fname ファイル名 //! @param [in] width 画像の幅 //! @param [in] height 画像の高さ //! @param [in] p 画像のメモリへのアドレス //! @details 1画素1Byteのメモリを渡すと、0,1テキストでファイル名fnameで書き込む void pbmP1_Write(const char* const fname, const int width, const int height, const unsigned char* const p); //! @brief フォントの読込 FreeType2の処理 //! @param [in] library FT_Library //! @param [in] fontfile フォントファイルへのパス //! @return フェイスオブジェクト FT_Face* my_LoadFonts( FT_Library& library, const char* fontfile ) { FT_Face* face = new FT_Face; FT_Error error; // フォントファイル読み込み error = FT_New_Face( library, fontfile, 0, face ); //文字コード指定 error = FT_Select_Charmap( *face, // target face object FT_ENCODING_UNICODE // エンコード指定 ); if (error == FT_Err_Unknown_File_Format) return nullptr; else if (error) return nullptr; int pixel_size_y = 64; error = FT_Set_Pixel_Sizes( *face, // handle to face object 0, // pixel_width pixel_size_y); // pixel_height return face; }
//! @brief HarfBuzzで計算した座標を使いFreeType2で文字列を描画する void my_FaceDraw(hb_buffer_t* hbbuf,FT_Face* face) { // 描画先をクリア std::fill(image.begin(), image.end(), 0); //文字数を格納 (書記素数ではない。例えば「あ゙」は2文字) unsigned int glyph_count; hb_glyph_info_t* glyph_info = hb_buffer_get_glyph_infos(hbbuf, &glyph_count); hb_glyph_position_t* glyph_pos = hb_buffer_get_glyph_positions(hbbuf, &glyph_count); hb_position_t cursor_x = 0; hb_position_t cursor_y = 0; // 各文字ごとに描画する for (unsigned int i = 0; i < glyph_count; i++) { // codepointという変数名だが実際にはグリフインデクスが入っている hb_codepoint_t glyphid = glyph_info[i].codepoint; // 一文字分のオフセット。本来描画される位置からどれぐらいずれるか hb_position_t x_offset = glyph_pos[i].x_offset >> 6;// 結合文字の゛は本来の位置より左側に描画するので hb_position_t y_offset = glyph_pos[i].y_offset >> 6;// x_offsetにはマイナスの値が入る // 次の文字の描画開始位置までのピクセル数 hb_position_t x_advance = glyph_pos[i].x_advance >> 6; hb_position_t y_advance = glyph_pos[i].y_advance >> 6; /////////////////////////////////////// /////////////////////////////////////// /////////////////////////////////////// FT_Error error = FT_Load_Glyph(*face, glyphid, FT_LOAD_RENDER); if (error) { continue; } // 文字を画像化 FT_Render_Glyph( (*face)->glyph, FT_RENDER_MODE_NORMAL); // 画像書き込み // オフセットを加えて座標調整する draw( (*face)->glyph->bitmap, cursor_x + x_offset + (*face)->glyph->bitmap_left, cursor_y + y_offset - (*face)->glyph->bitmap_top + 100 ); /////////////////////////////////////// /////////////////////////////////////// /////////////////////////////////////// // 次の文字の描画開始値 cursor_x += x_advance; cursor_y += y_advance; } }
int main() { FT_Library library; // handle to library FT_Error error; error = FT_Init_FreeType(&library); if (error) return -1; ///////////////////////////////////////////// FT_Face* face_jp = my_LoadFonts(library, "C:\\Windows\\Fonts\\msgothic.ttc"); //////////////////////// hb_font_t* hbfont; hb_buffer_t* hbbuf; //////////////////////// std::u32string text = U"あ゙いう"; //////////////////////// hbbuf = hb_buffer_create(); hb_buffer_add_utf32(hbbuf, (const std::uint32_t*)text.data(), -1, 0, -1);// 描画したいテキストの設定 hb_buffer_set_direction(hbbuf, HB_DIRECTION_LTR);// 文字の方向を左から右として設定 hb_buffer_set_script(hbbuf, HB_SCRIPT_HIRAGANA);// Unicodeの用字(Script)として日本語を指定 hb_buffer_set_language(hbbuf, hb_language_from_string("jp", -1));// 言語として日本語を設定 //////////////////////// hbfont = hb_ft_font_create(*face_jp, nullptr); hb_shape(hbfont, hbbuf, NULL, 0); //////////////////////// my_FaceDraw(hbbuf, face_jp);//FreeType2とHarfBuzzで文字列描画 //////////////////////// hb_buffer_destroy(hbbuf);// バッファ破棄 hb_font_destroy(hbfont); // フォント破棄 //////////////////////// FT_Done_Face(*face_jp); pbmP1_Write("C:\\test\\freetypetest_mgj.pbm", imageWidth, imageHeight, &image[0]); ///////////////////////////////////////////// // FreeType2の解放 FT_Done_FreeType(library); }
//! @brief imageへbmpの内容を書き込む //! @param [in] bmp 文字画像 //! @param [in] startx image画像内の書き込み開始位置 //! @param [in] starty image画像内の書き込み開始位置 void draw(const FT_Bitmap& bmp, int startx, int starty) { int Width = bmp.width; int Height = bmp.rows; for (size_t y = 0; y < Height; y++) { for (size_t x = 0; x < Width; x++) { int xx = startx + x; int yy = starty + y; #if 0 if (x == 0 || y == 0 || x == Width - 1 || y == Height - 1) { image[pixel_pos(xx, yy)] = 1; } #endif if (xx < 0)continue; if (yy < 0)continue; if (xx >= imageWidth)continue; if (yy >= imageHeight)continue; if (bmp.buffer[y * Width + x]) { image[pixel_pos(xx, yy)] = 1; } } } } //! @brief PBM(1byte,テキスト)を書き込む //! @param [in] fname ファイル名 //! @param [in] width 画像の幅 //! @param [in] height 画像の高さ //! @param [in] p 画像のメモリへのアドレス //! @details 1画素1Byteのメモリを渡すと、0,1テキストでファイル名fnameで書き込む void pbmP1_Write(const char* const fname, const int width, const int height, const unsigned char* const p) { // PPM ASCII FILE* fp = fopen(fname, "wb"); fprintf(fp, "P1\n%d\n%d\n", width, height); size_t k = 0; for (size_t i = 0; i < (size_t)height; i++) { for (size_t j = 0; j < (size_t)width; j++) { fprintf(fp, "%d ", p[k] ? 0 : 1); k++; } fprintf(fp, "\n"); } fclose(fp); }
続く。
HarfBuzzをCMake
HarfBuzzはFreeType2で文字を描くときにレイアウトを調整するライブラリ。
まず、harfbuzz-3.2.0をダウンロードする。
https://harfbuzz.github.io/install-harfbuzz.html

github.com/harfbuzz/harfbuzz/releases から、以下へ飛び、Source code (zip) からダウンロードする
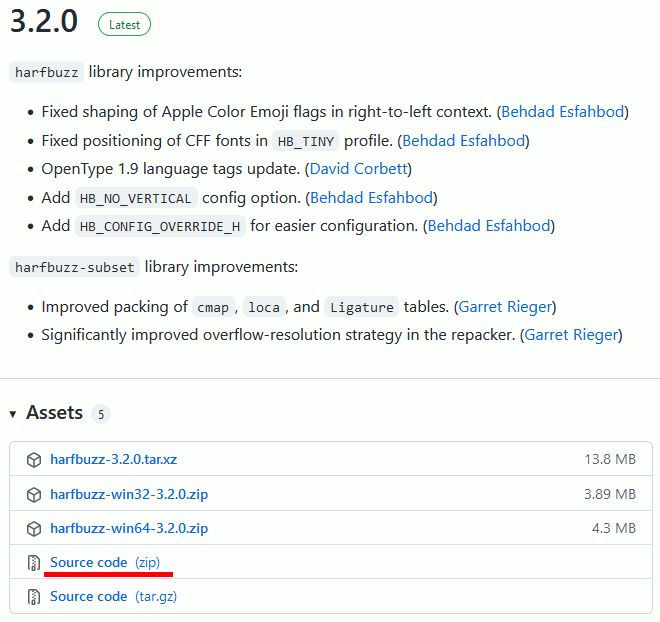
harfbuzz-3.2.0 ... 展開したフォルダ
harfbuzz-sln ... CMakeで作ったsolutionが入るフォルダ
harfbuzz-install BUILD→INSTALLでライブラリが入るフォルダ
freetype2-install ... コンパイル済みのfreetype2
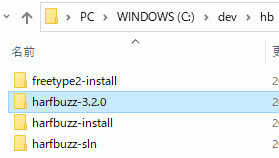
注意として、FreeType2はコンパイル済みとする。
CMake
三回Configureする。
一回目はただConfigureする。
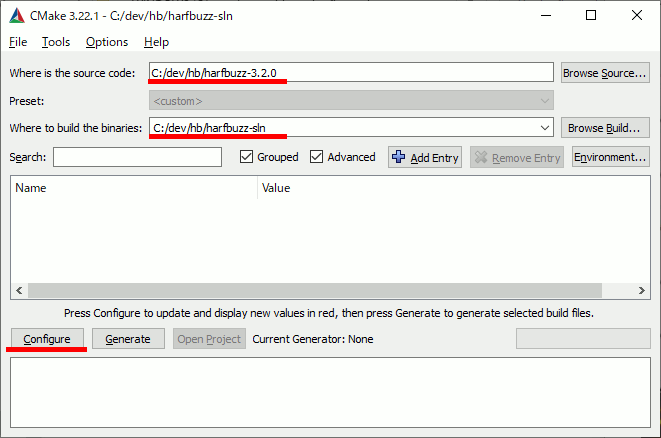
二回目は、CMAKE_INSTALL_PREFIXに、インストール先のパスを指定。
続いて、HB → HB_HAVE_FREETYPE のチェックを入れる。
再びConfigureする。
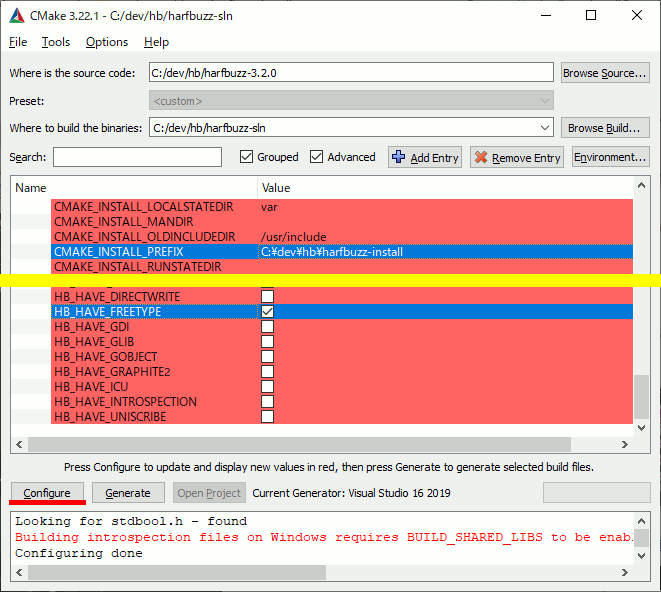
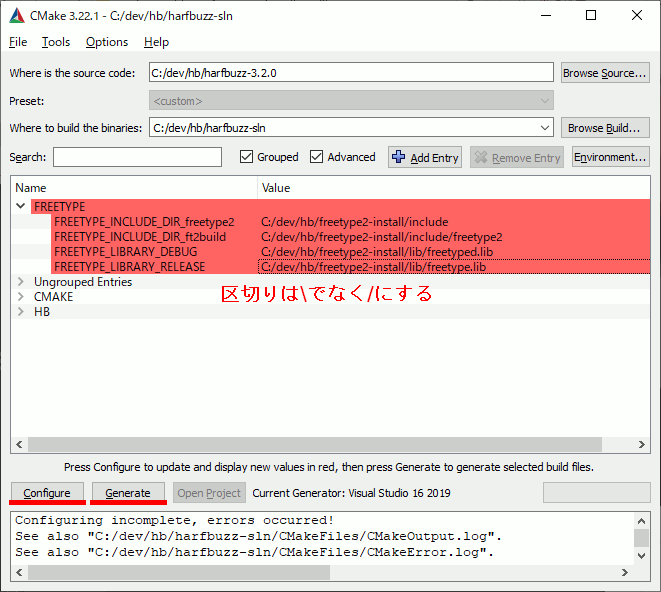
FREETYPEをチェックしたのでFREETYPEのパスを指定する。
これでConfigureし、Generateする。
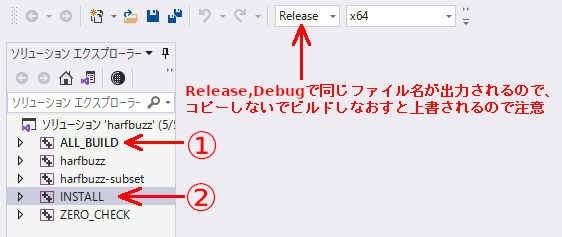
VC++でビルド
ALL_BUILDしてINSTALLする。Release版、Debug版が同じファイル名で出力されるので、両方ほしい場合は先に作ったほうをコピーしておく必要がある。