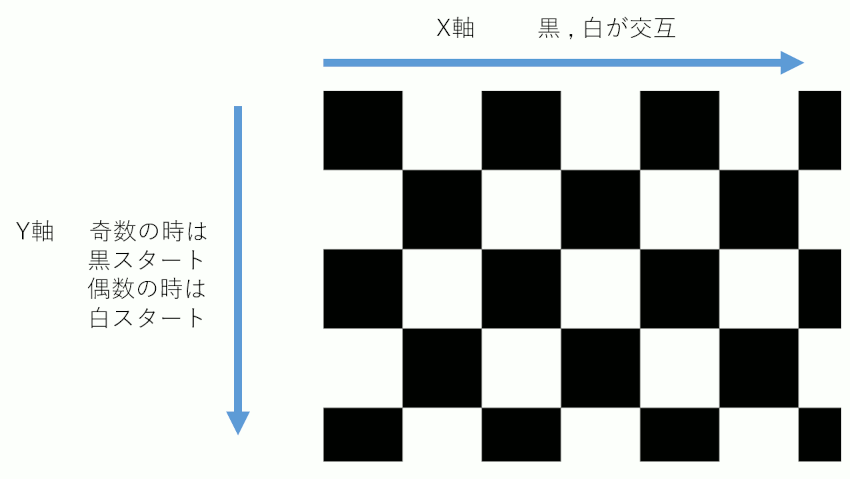
ビット演算で市松模様を描く
前にも書いたことがあるが、ビット演算で書き直す。
排他的論理和は、1^1、0^0の時は0、それ以外の時は1になる。
これを使い、x軸が偶数、奇数、偶数、奇数、...と並んでいるものに、y軸が偶数の時は奇数だけを1、y軸が奇数の時は偶数だけを1にすることで市松模様にする。

#include <iostream> #include <vector> #pragma warning(disable:4996) void pnmP2_Write( const char* const fname, const int width, const int height, const unsigned char* const p); int main() { int w = 100, h = 50; int size = w * h; std::vector<unsigned char> image(w*h); for (size_t y = 0; y < h; y++) { for (size_t x = 0; x < w; x++) { size_t p = y * w + x; int f; /* if (y % 2) { f = (x % 2)? 1 : 0; } else { f = (x % 2) ? 0 : 1; } */
f = (x & 1) ^ (y & 1);
image[p] = f * 255; } } pnmP2_Write(R"(C:\Users\szl\Desktop\mydev\out\a.pgm)", w, h, image.data()); } //! @brief Portable Gray map //! @param [in] fname ファイル名 //! @param [in] width 画像の幅 //! @param [in] height 画像の高さ //! @param [in] p 画像のメモリへのアドレス //! @details RGBRGBRGB....のメモリを渡すと、RGBテキストでファイル名fnameで書き込む void pnmP2_Write( const char* const fname, const int width, const int height, const unsigned char* const p) { // PPM ASCII FILE* fp = fopen(fname, "wb"); fprintf(fp, "P2\n%d %d\n%d\n", width, height, 255); size_t k = 0; for (size_t i = 0; i < (size_t)height; i++) { for (size_t j = 0; j < (size_t)width; j++) { fprintf(fp, "%d ", p[k]); k++; } fprintf(fp, "\n"); } fclose(fp); }

余談
今の時代は鬼滅の刃とかキーワードに入れておいたほうがヒットしやすいのだろうか。
XMLパーサーpugixml を試す(読み込み,日本語)
マルチバイトであればタグが日本語でも動作するが、Unicodeの場合タグが英語でなければ取得できない。
マルチバイトの場合
#include <iostream> #include <string> #include "pugixml.hpp"
const char* data() { return R"( <?xml version="1.0" encoding="Shift-JIS"?> <data date="2022-06-15"> <名前> <a>田中</a> <b>中山</b> <c>山本</c> </名前> </data> )"; }
int main() { pugi::xml_document doc; std::string txt = data(); pugi::xml_parse_result result = doc.load_buffer(txt.data(), txt.size(), 0,pugi::xml_encoding::encoding_auto); std::cout << doc.child("data").attribute("date").value() << std::endl; for (auto point : doc.child("data").children("名前")) { std::cout << point.name() << std::endl; for (auto val : point.children()) { std::cout << val.name() << " : " << val.child_value() << std::endl; } } }
utf8の場合
#include <iostream> #include <string> #include "pugixml.hpp"
const char* data() { return u8R"( <?xml version="1.0" encoding="UTF-8"?> <data date="2022-06-15"> <names> <a>田中</a> <b>中山</b> <c>山本</c> </names> </data> )"; }
int main() { std::wcout.imbue(std::locale("")); pugi::xml_document doc; pugi::xml_parse_result result = doc.load_string(data()); std::cout << doc.child("data").attribute("date").value() << std::endl; for (auto point : doc.child("data").children("names")) { std::cout << point.name() << std::endl; for (auto val : point.children()) { std::wcout << pugi::as_wide(val.name()) << " : " << pugi::as_wide(val.child_value()) << std::endl; } } }
XMLパーサーpugixml を試す(作成)
#include <iostream> #include <sstream> #include <fstream> #include "pugixml.hpp" int main() { pugi::xml_document doc; pugi::xml_node theroot = doc.append_child("the_root"); pugi::xml_node tag1 = theroot.append_child("tag1"); tag1.append_child(pugi::node_pcdata).set_value("This "); tag1.append_child(pugi::node_pcdata).set_value("is "); tag1.append_child(pugi::node_pcdata).set_value("a "); tag1.append_child(pugi::node_pcdata).set_value("pen "); pugi::xml_node tag2 = theroot.insert_child_after("tag2", tag1); tag2.append_child(pugi::node_pcdata).set_value("tag2item"); pugi::xml_node noclose = theroot.insert_child_after("no_close", tag1); noclose.append_attribute("text") = "abc"; noclose.append_attribute("float") = 1.1; std::stringstream ss; doc.save(ss); std::cout << ss.str() << std::endl; // 表示ならこれもできる // doc.save(std::cout); // ファイル出力 // std::ofstream outf("test.xml"); // doc.save(outf); }
XMLパーサーpugixml を試す(読み込み)
MIT LicenseのXMLパーサー。

#include <iostream> #include "pugixml.hpp"
const char* data() { return R"( <?xml version="1.0"?> <data date="2022-06-15"> <point> <x>10.0</x> <y>12.0</y> <z>15.0</z> <r>255</r> <g>0</g> <b>0</b> </point> <point> <x>20.0</x> <y>22.0</y> <z>25.0</z> <r>0</r> <g>255</g> <b>0</b> </point> </data> )"; }
int main() { pugi::xml_document doc; //pugi::xml_parse_result result = doc.load_file("tree.xml"); //ファイルから読み込む場合 pugi::xml_parse_result result = doc.load_string(data()); std::cout << doc.child("data").attribute("date").value() << std::endl; for (auto point : doc.child("data").children("point")) { std::cout << point.name() << std::endl; for (auto val : point.children()) { std::cout << val.name() << " : " << val.child_value() << std::endl;// 値の取得にはtext()かchild_value()を使う } } }
出力
point
x : 10.0
y : 12.0
z : 15.0
r : 255
g : 0
b : 0
point
x : 20.0
y : 22.0
z : 25.0
r : 0
g : 255
b : 0
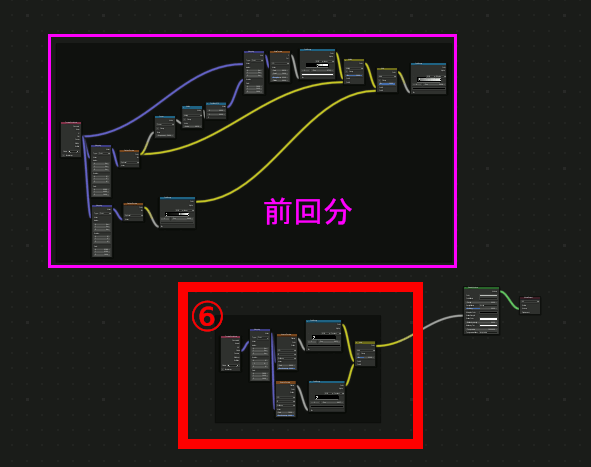
Blenderのテクスチャを渦巻にする理屈
前に試したBlenderのボリュームで銀河を作るやつで、テクスチャを渦巻状にしていた。
Create a Galaxy in Blender – Iridesiumを試す(1)
改めて説明しろと言われるとやりにくいのでまとめておく。

モデルにテクスチャが張り付いているとき、モデル上のある点の色は、テクスチャ上のどこかからとってきている。従って、テクスチャ座標を変換することでずらしたりできる。
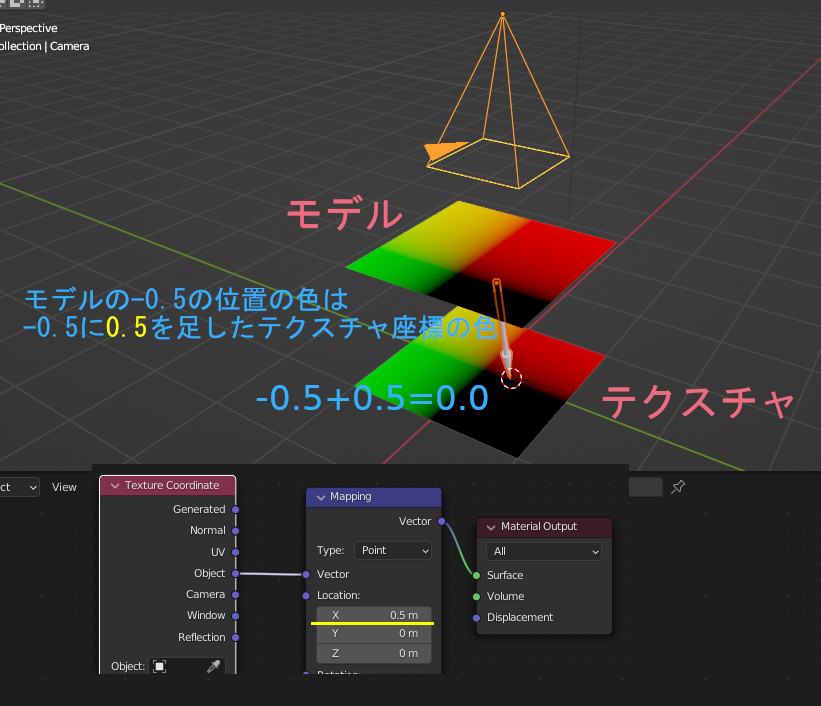
テクスチャ座標をただ回転させただけでは、テクスチャが回るだけで渦巻にはならない。
テクスチャが回転するだけなのは、モデル上の全ての位置で、同じ回転量だけ変化させてテクスチャの色をとってくるからで、つまり、モデル上の場所によって回転量を変化させれば、歪んだ座標系の色が取得できる。
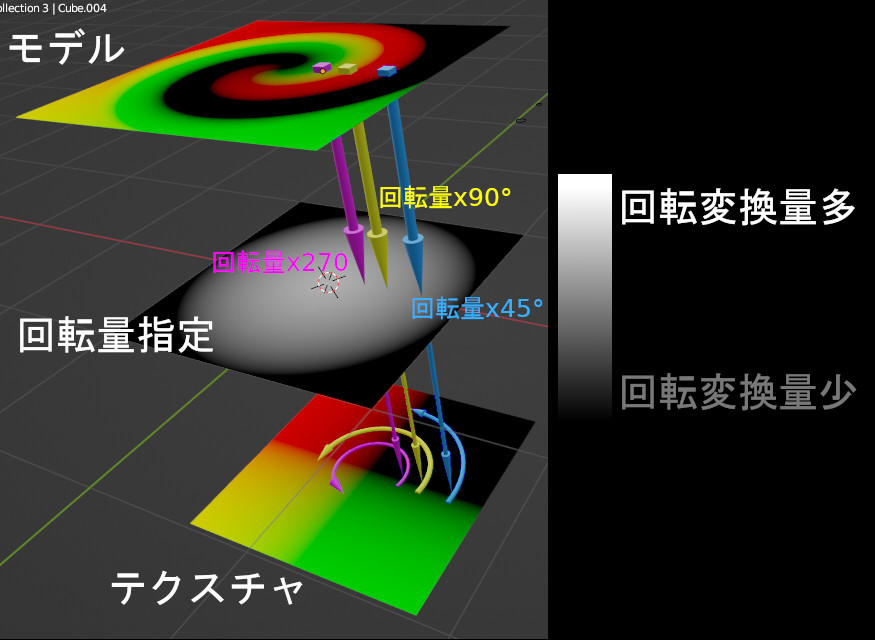
モデル上のある点の色を決めるとき、「テクスチャのどの位置から色をとってくるか」を求める際に、その座標をアフィン変換してやるのがmappingで、そこで回転を指定し、回転量としてGradientTextureを与えることで、場所によって回転量を変化させることができる。
Win32api でクリップボードにデータがコピーされたら動くプログラム
クリップボードを監視する方法を調べてみたら、AddClipboardFormatListenerにウィンドウハンドルを渡しておけば、クリップボードにコピーが発生するたびにWM_CLIPBOARDUPDATEメッセージが入ってくることが分かったのでこれを使うとクリップボードを管理するようなプログラムを書ける。
LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam) { switch (message) { case WM_CREATE: // クリップボード監視開始 AddClipboardFormatListener(hWnd); return 0; case WM_CLIPBOARDUPDATE: // クリップボードが使用されるとこのメッセージが入る if (OpenClipboard(hWnd)) { // クリップボードの内容がテキストの時だけ処理 if ((IsClipboardFormatAvailable(CF_TEXT) == TRUE)) { HGLOBAL hg = GetClipboardData(CF_TEXT); size_t size = GlobalSize(hg); LPVOID strClip = GlobalLock(hg); char* strText = new char[size]; strcpy(strText, (char*)strClip); //クリップボード後始末 GlobalUnlock(hg); CloseClipboard(); // 表示 HDC hdc = GetDC(hWnd); RECT rect{ 0,0,100,100 }; DrawTextA(hdc, (char*)strText, -1, &rect, DT_LEFT); ReleaseDC(hWnd, hdc); } } return 0; case WM_LBUTTONDOWN: return 0; case WM_DESTROY: // クリップボード監視終了 RemoveClipboardFormatListener(hWnd); PostQuitMessage(0); break; case WM_PAINT: { PAINTSTRUCT ps; HDC hdc = BeginPaint(hWnd, &ps); EndPaint(hWnd, &ps); } break; default: return DefWindowProc(hWnd, message, wParam, lParam); } return 0; }
このコードは、クリップボードに文字列がコピーされると画面にその内容を表示する。
Create a Galaxy in Blender – Iridesiumを試す(2)
前回
Create a Galaxy in Blender – Iridesiumを試す(1)
小さな星をちりばめるテクスチャを作成。
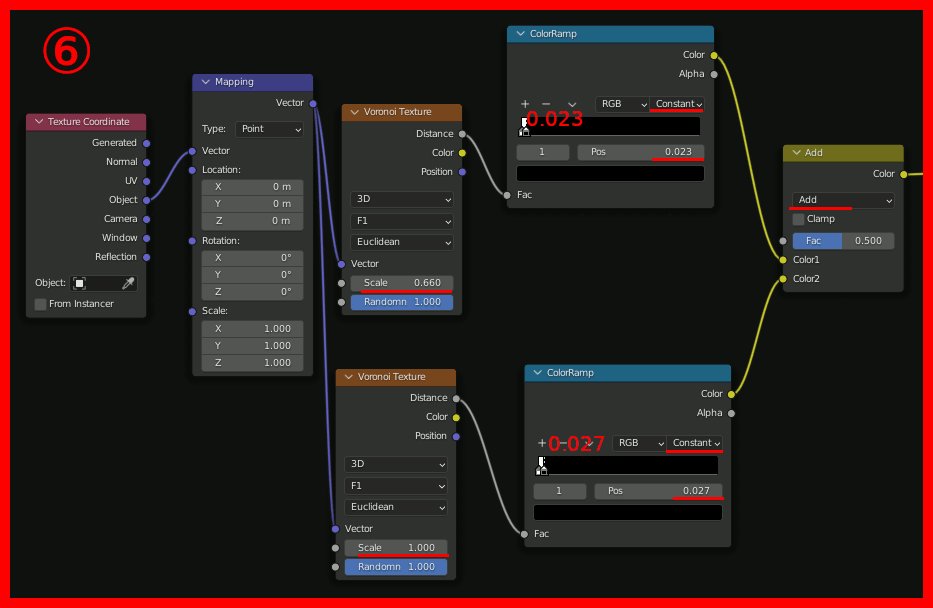
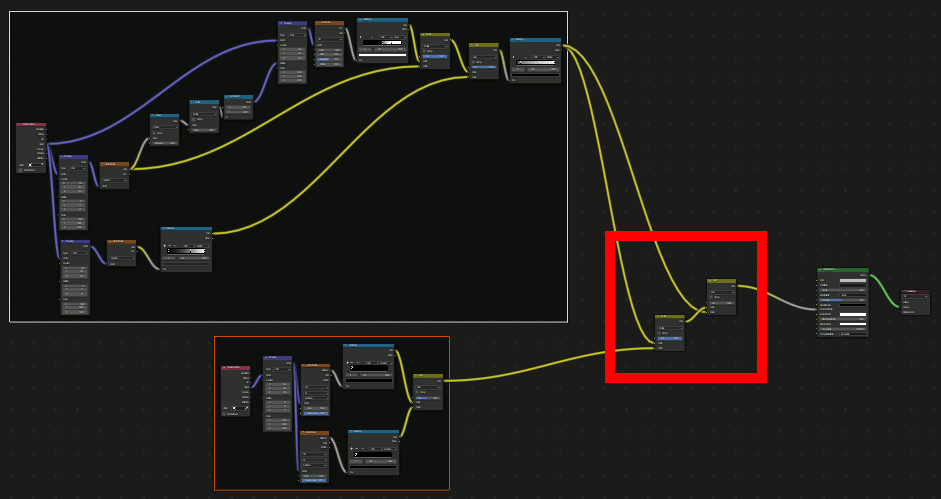
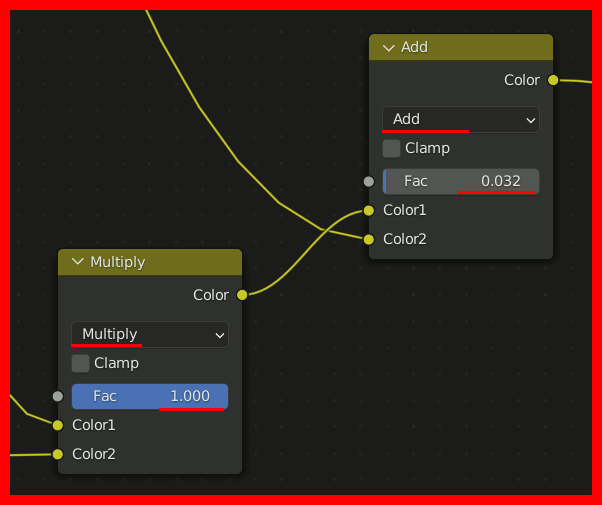
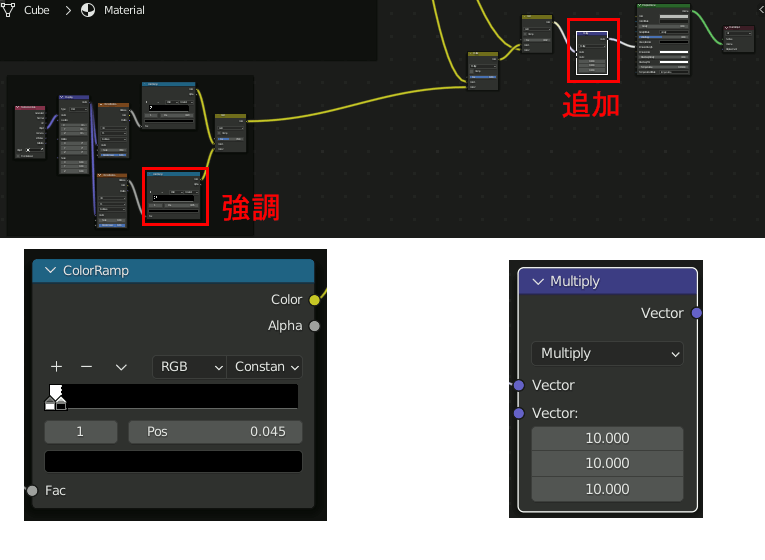
注意:あまりに見えづらい場合は強調させて作業を進める。(動画には入っていない)

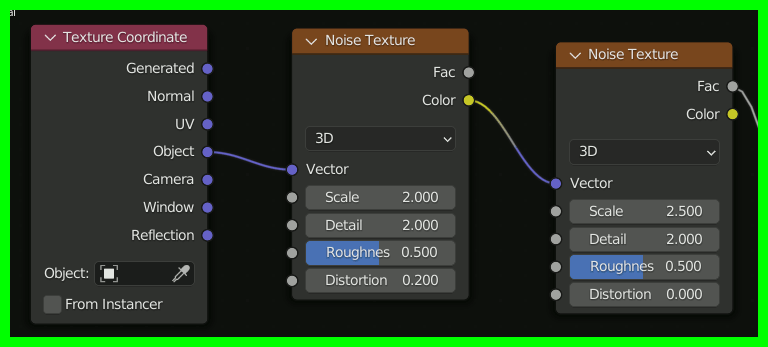
さらに、星雲にノイズを加えてよりそれらしくする
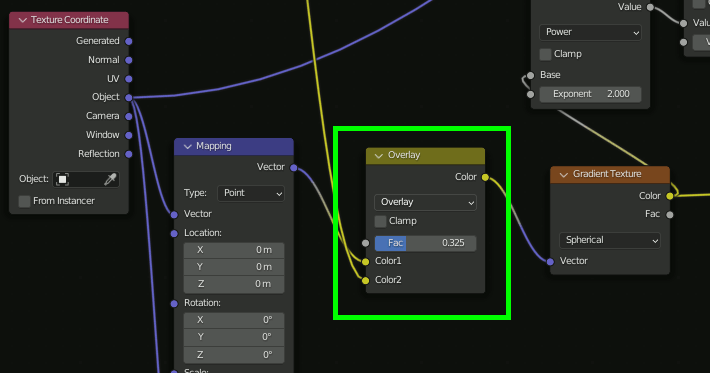

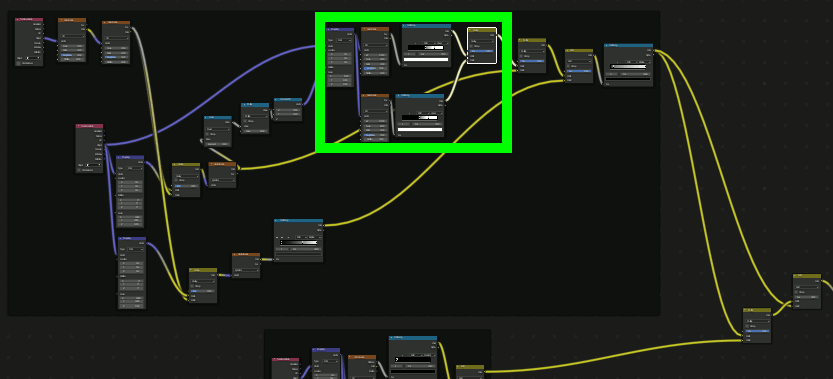
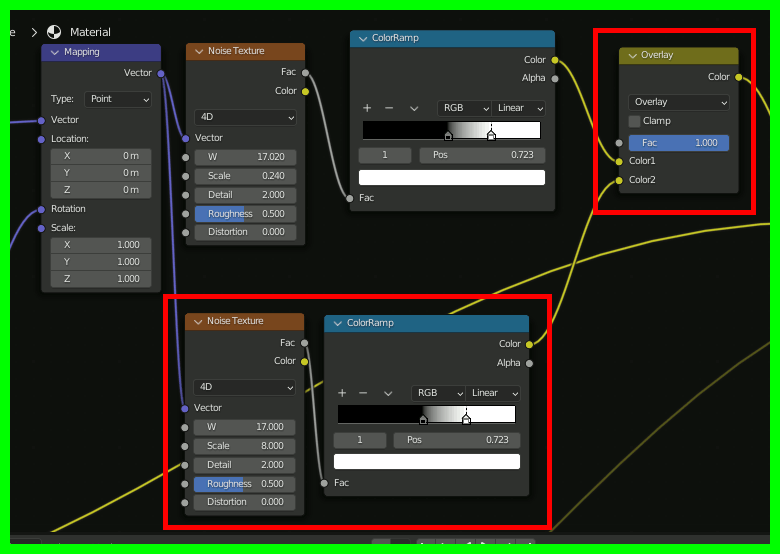
着色
結果
いろいろと調整して以下のように出来上がる。

Create a Galaxy in Blender – Iridesiumを試す(1)
https://www.youtube.com/watch?v=HCBW4fNAjBg
try-blender-tutorial-Create-a-Galaxy-in-Blender-Iridesium-2
Create a Galaxy in Blender – Iridesiumを試す(2)
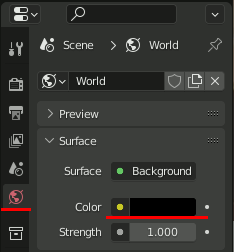
最初に背景を黒にしておく。
次にCubeを追加。座標系をObjectにするのでX,Y方向にやや大きめのSphereを追加する。
ここでは30x30x2の直方体とする。
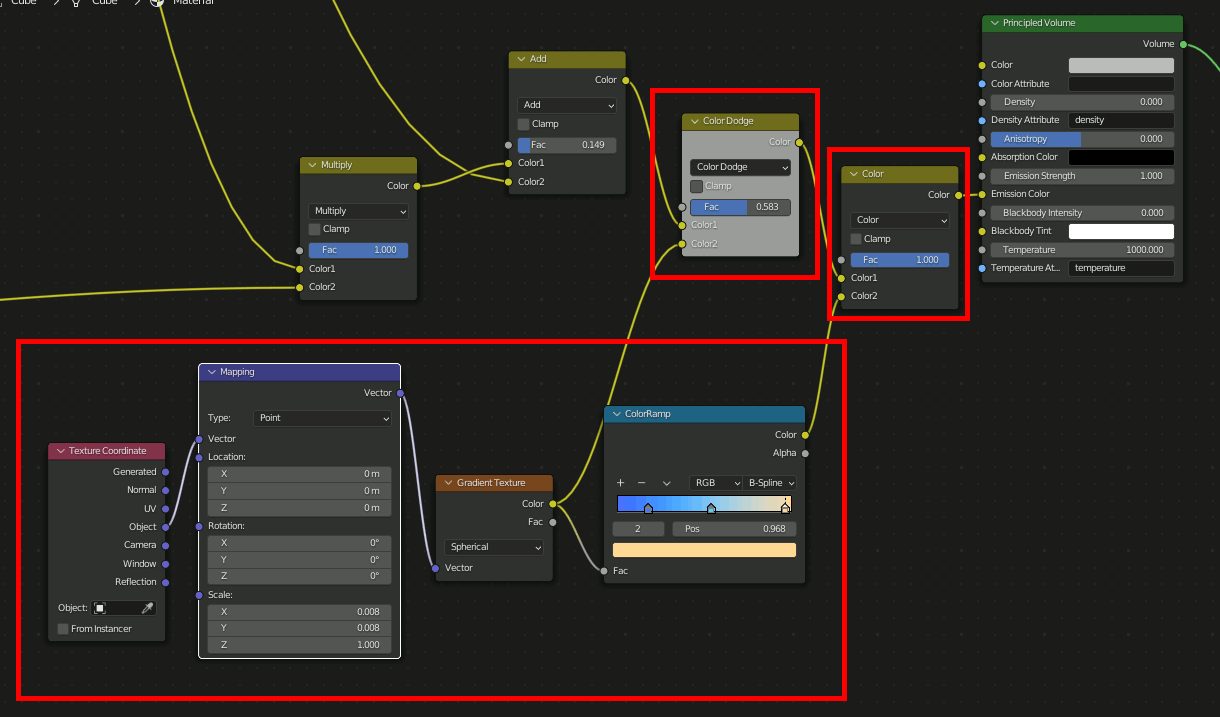
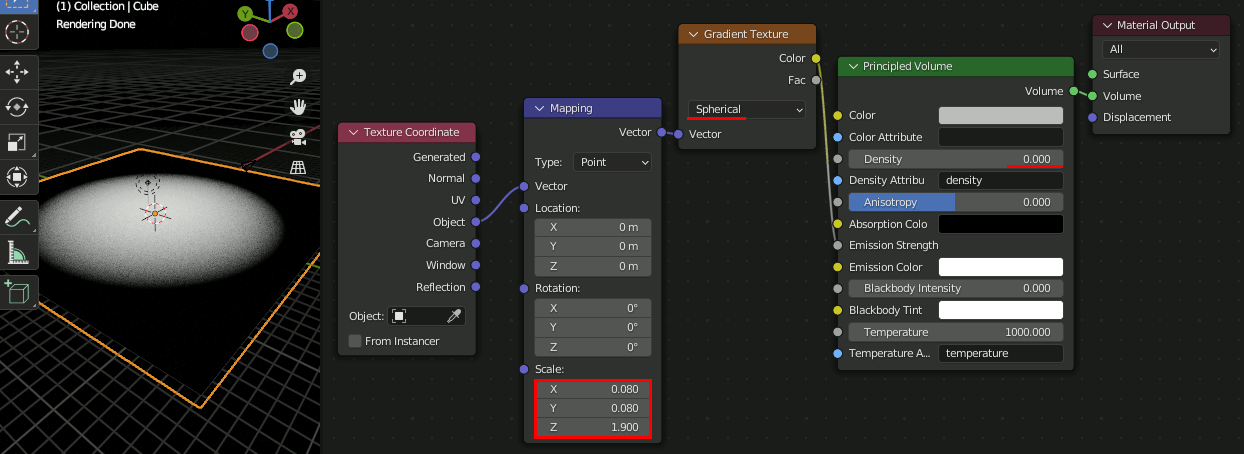
CubeにVolumeを追加し以下のように設定。
注:図ではPrincipled VolumeのEmission StrengthにつながっているがEmission Colorが正しい。
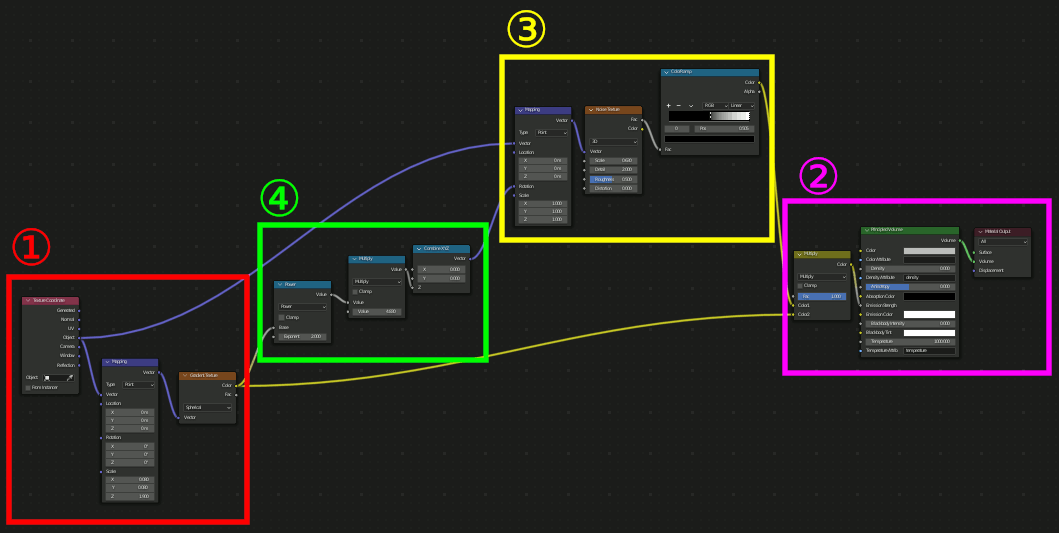
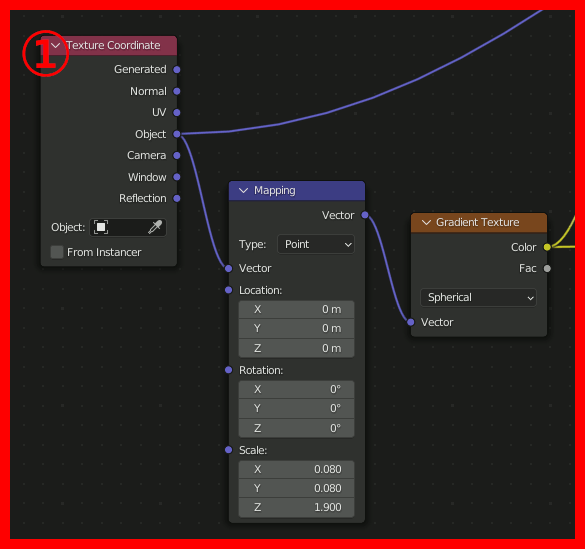
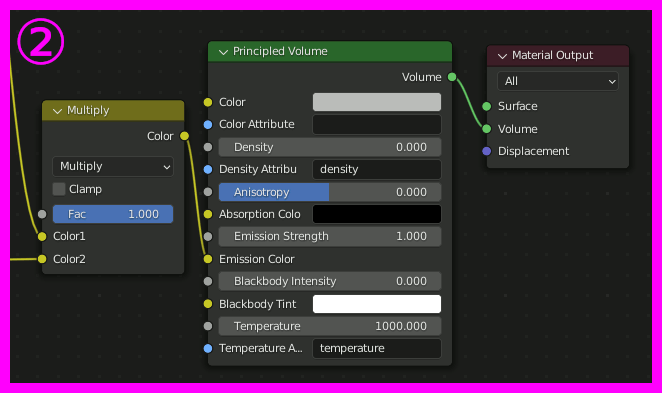
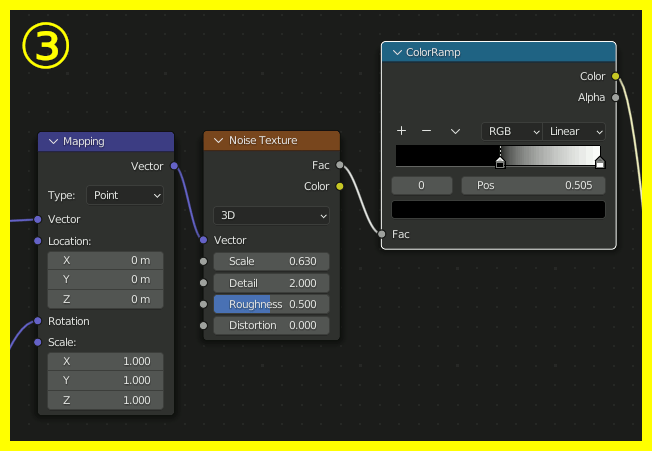
④、ここが最も重要な場所で、Gradient TextureのSpherical(=球状のグラデーション)をMappingのRotationに接続する。これによって中央から外側にかけて回転量を変化させ渦巻状を作成する。渦巻の巻き具合はGradient Textureの値に対するMathで調節する。
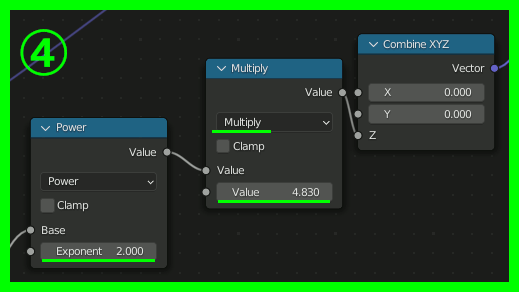
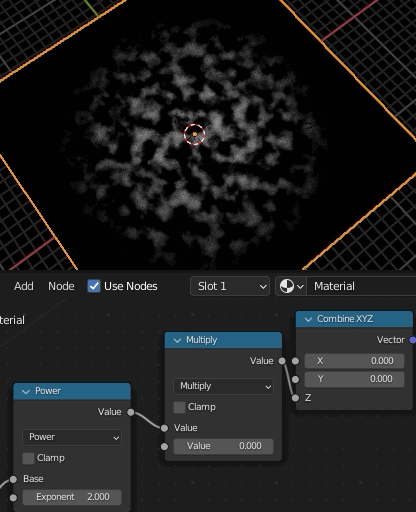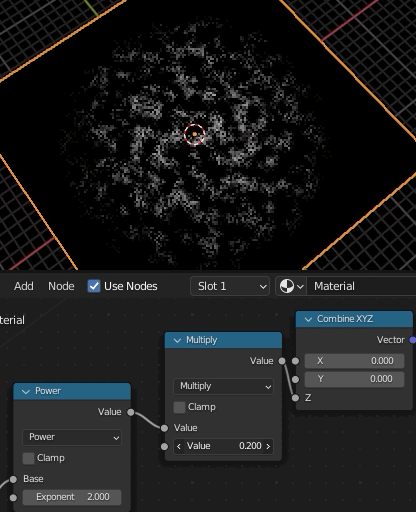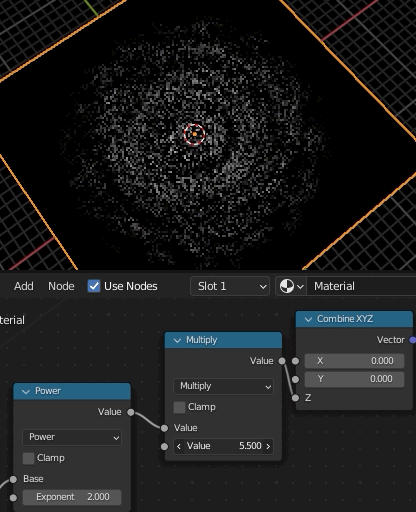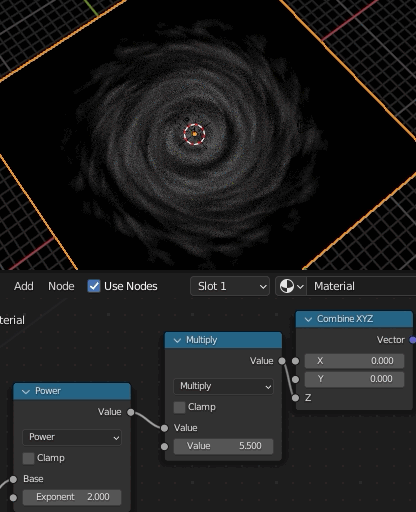
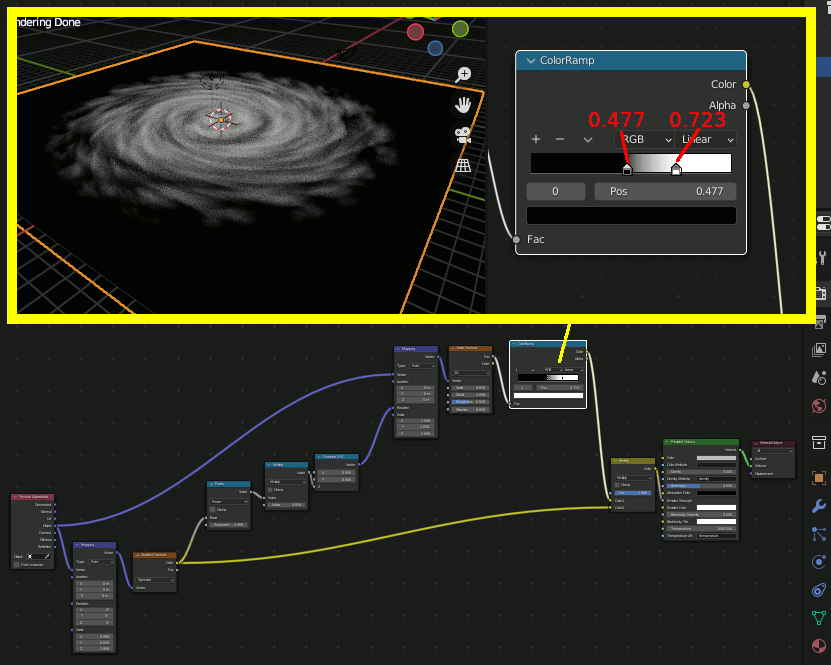
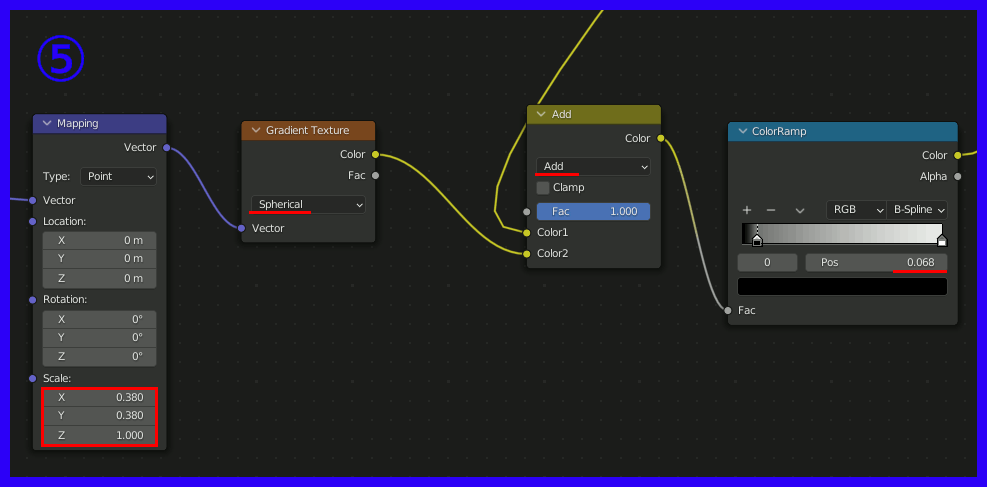
ここまでが基本的なアイデアとのこと。
続く。
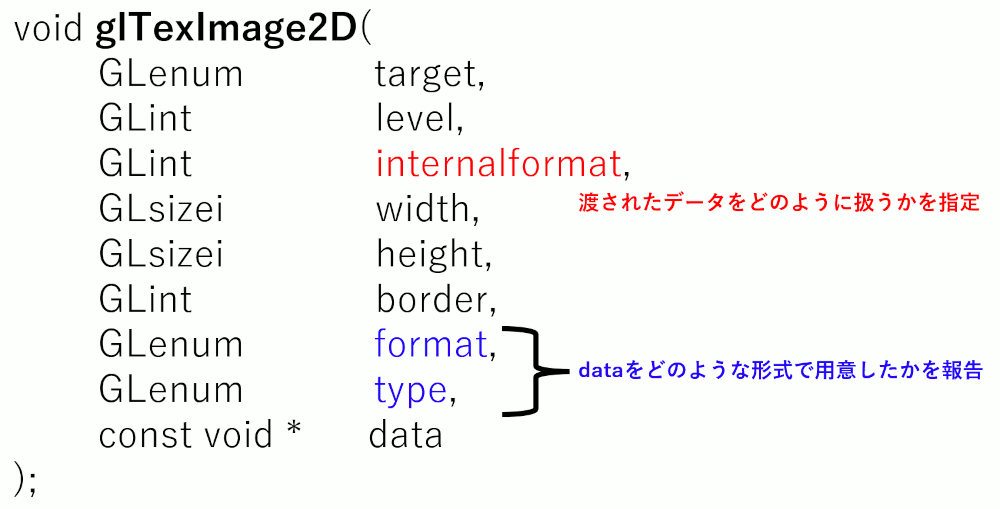
glTexImage2D internalformat vs format
format,typeはテクスチャとして用意したメモリの形式。
internalformatはそれをOpenGLがどのように使うかを指定する。
#include <iostream> #include <array> #include <Windows.h> // GL_BGRなどを使うにはglew.hが必要。自分で定義してもいい #include <GL/glew.h> #include <gl/GL.h> #include <gl/GLU.h> #include <gl/freeglut.h> GLuint texName; //ウィンドウの幅と高さ int width, height; //描画関数 void disp(void) { glViewport(0, 0, width, height); glClearColor(0.2, 0.2, 0.2, 1); glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT); //glEnable(GL_CULL_FACE); double v = 0.7; glEnable(GL_TEXTURE_2D); glBindTexture(GL_TEXTURE_2D, texName); glBegin(GL_QUADS); glTexCoord2f(0, 0); glVertex2f(-0.9, -0.9); glTexCoord2f(0, 1); glVertex2f(-0.9, 0.9); glTexCoord2f(1, 1); glVertex2f(0.9, 0.9); glTexCoord2f(1, 0); glVertex2f(0.9, -0.9); glEnd(); glFlush(); } //ウィンドウサイズの変化時に呼び出される void reshape(int w, int h) { width = w; height = h; disp(); } //エントリポイント int main(int argc, char** argv) { glutInit(&argc, argv); glutInitWindowPosition(100, 50); glutInitWindowSize(500, 500); glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA); glutCreateWindow("sample"); glutDisplayFunc(disp); glutReshapeFunc(reshape); glEnable(GL_TEXTURE_2D); glGenTextures(1, &texName); glBindTexture(GL_TEXTURE_2D, texName); glPixelStorei(GL_UNPACK_ALIGNMENT, 1); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); const int TEXSIZE = 2; std::array<unsigned char, 3> texrgb[TEXSIZE * TEXSIZE]; texrgb[0] = std::array<unsigned char, 3>{255, 0, 0 }; texrgb[1] = std::array<unsigned char, 3>{ 0, 255, 0 }; texrgb[2] = std::array<unsigned char, 3>{ 0, 0, 255}; texrgb[3] = std::array<unsigned char, 3>{255, 128, 0}; #if 0 // formatをGL_RGBにした場合 glTexImage2D( GL_TEXTURE_2D, 0, GL_RGB, // internalformat TEXSIZE, TEXSIZE,0, GL_RGB, // format GL_UNSIGNED_BYTE, &texrgb[0] ); #else // formatをGL_BGRにした場合 glTexImage2D( GL_TEXTURE_2D, 0, GL_RGB, // internalformat TEXSIZE, TEXSIZE,0, GL_BGR, // format GL_UNSIGNED_BYTE, &texrgb[0] ); #endif glutMainLoop(); return 0; }
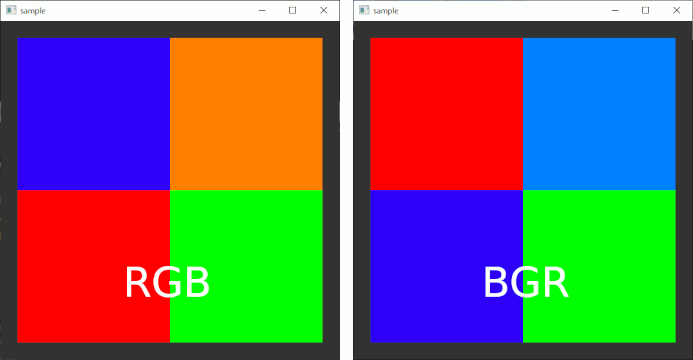
上の例では、例えば{255,0,0}というデータを用意する。これをformatで「RGBの順にデータが並んでいますよ」と指定すると、internalformatで「RGBのテクスチャを使う」と指定してあるので、赤いドットとなる。
逆に、「BGRの順にデータが並んでいますよ」と指定すると、internalformatで「RGBのテクスチャを使う」と指定してあるので、BGRの順にデータが並んでいることを考慮し、青いドットとなる。
このように、「formatでデータの並び方を確認し、internalformatで指定した解釈でテクスチャとして利用する」ので、「formatで指定した形式からinternalformatで指定した形式に変換されている」といえる。
厄介なのがほとんどの場合この変換をしてくれないので、実質組み合わせが決まっているようなものになっている。
PCLのpcl::getMeanStdDevは不偏標準偏差を返す
まず以下のプログラムを実行する。
#include <iostream> #include <pcl/common/impl/common.hpp> //getMeanStdDev #pragma comment(lib,"pcl_commond.lib") int main() { std::vector<float> v; v.push_back(-1.841658711); v.push_back(-1.449076772); v.push_back(-1.04681015); v.push_back(-0.646572888); v.push_back(-0.25920701); v.push_back(0.149769783); v.push_back(-1.883069754); v.push_back(-1.481496215); v.push_back(-1.083532453); //不偏標準偏差 double mean, stddev; pcl::getMeanStdDev(v, mean, stddev); printf("平均:%lf\n", mean); printf("不偏標準偏差%lf\n", stddev); }
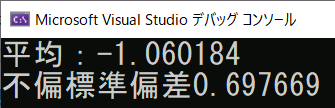
Excelで確認
Excelでは、母標準偏差(nで割る方)をSTDEV.P、不偏標準偏差(n-1で割る方)をSTDEV.Sで計算する。

母標準偏差と不偏標準偏差の違いは、母標準偏差は母集団に対して使うのに対して、不偏標準偏差は母集団の標本、つまり元データをサンプリングしたデータに対して使う。