ImageMagickでアニメーションpng,gif,webpを作成
アニメーション gif (1.96 MB)

アニメーション webp (607 KB)

アニメーション png (5.15MB)

マニフェストを追加してwin32apiのUIにVisualStyleを適用する
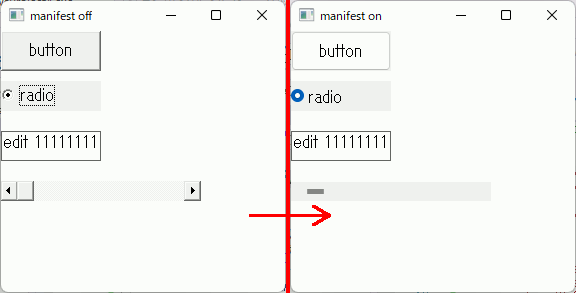
パターン1 プログラム先頭に#pragma commentを設定する
#pragma comment(linker,"\"/manifestdependency:type='win32' \
name='Microsoft.Windows.Common-Controls' version='6.0.0.0' \
processorArchitecture='*' publicKeyToken='6595b64144ccf1df'
language='*'\"")
https://learn.microsoft.com/ja-jp/windows/win32/controls/cookbook-overview
#include <windows.h> // ビジュアルスタイル適用 #pragma comment(linker,"\"/manifestdependency:type='win32' \ name='Microsoft.Windows.Common-Controls' version='6.0.0.0' \ processorArchitecture='*' publicKeyToken='6595b64144ccf1df' language='*'\"") LRESULT CALLBACK WndProc(HWND hwnd, UINT msg, WPARAM wp, LPARAM lp) { switch (msg) { case WM_DESTROY: PostQuitMessage(0); return 0; } return DefWindowProc(hwnd, msg, wp, lp); } int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, PSTR lpCmdLine, int nCmdShow) { HWND hwnd; MSG msg; WNDCLASS winc; winc.style = CS_HREDRAW | CS_VREDRAW; winc.lpfnWndProc = WndProc; winc.cbClsExtra = winc.cbWndExtra = 0; winc.hInstance = hInstance; winc.hIcon = LoadIcon(NULL, IDI_APPLICATION); winc.hCursor = LoadCursor(NULL, IDC_ARROW); winc.hbrBackground = (HBRUSH)GetStockObject(WHITE_BRUSH); winc.lpszMenuName = NULL; winc.lpszClassName = TEXT("SZLWND"); if (!RegisterClass(&winc)) return -1; hwnd = CreateWindow( TEXT("SZLWND"), TEXT("manifest on"), WS_OVERLAPPEDWINDOW | WS_VISIBLE, CW_USEDEFAULT, CW_USEDEFAULT, 300, 300, NULL, NULL, hInstance, NULL ); CreateWindow( TEXT("BUTTON"), TEXT("button"), WS_CHILD | WS_VISIBLE | BS_PUSHBUTTON, 0, 0, 100, 40, hwnd, NULL, hInstance, NULL ); CreateWindow( TEXT("BUTTON"), TEXT("radio"), WS_CHILD | WS_VISIBLE | BS_AUTORADIOBUTTON, 0, 50, 100, 30, hwnd, NULL, hInstance, NULL ); CreateWindow( TEXT("EDIT"), TEXT("edit 111111111111111111"), WS_CHILD | WS_VISIBLE | WS_BORDER | ES_LEFT , 0, 100, 100, 30, hwnd, NULL,hInstance, NULL ); CreateWindow( TEXT("SCROLLBAR"), TEXT(""), WS_CHILD | WS_VISIBLE | SBS_HORZ, 0, 150, 200, 20, hwnd, NULL,hInstance, NULL ); if (hwnd == NULL) return -1; while (GetMessage(&msg, NULL, 0, 0)) DispatchMessage(&msg); return msg.wParam; }
パターン2 マニフェストファイルをプロジェクトに追加
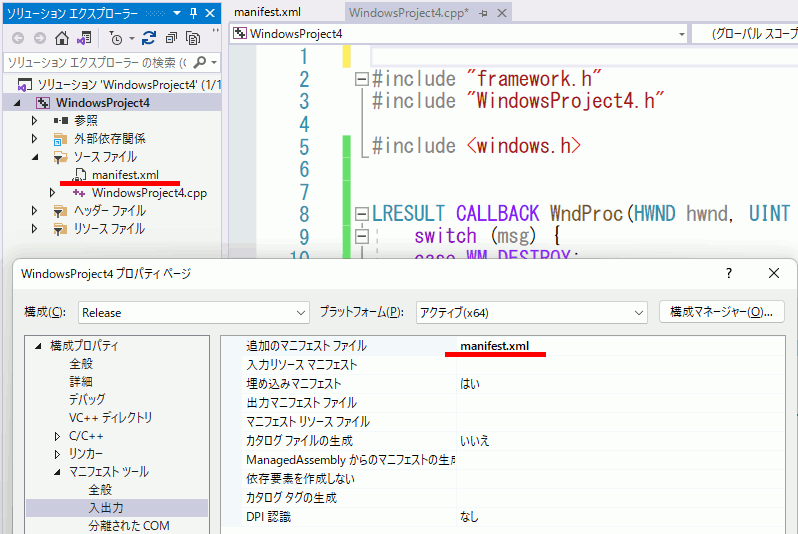
manifest.xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <assembly xmlns="urn:schemas-microsoft-com:asm.v1" manifestVersion="1.0"> <assemblyIdentity version="1.0.0.0" processorArchitecture="*" name="CompanyName.ProductName.YourApplication" type="win32" /> <description>Your application description here.</description> <dependency> <dependentAssembly> <assemblyIdentity type="win32" name="Microsoft.Windows.Common-Controls" version="6.0.0.0" processorArchitecture="*" publicKeyToken="6595b64144ccf1df" language="*" /> </dependentAssembly> </dependency> </assembly>
condaでopen3dをインストールする(改)
公式の方法ではcondaでopen3dを入れられない。というかopen3d 0.15からpip推奨になっているらしい。
しかしpipはcondaの他の環境に影響を与えるので、使いたくない。
公式の方法:
エラー
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source.
Collecting package metadata (repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Solving environment: \
Found conflicts! Looking for incompatible packages.
This can take several minutes. Press CTRL-C to abort.
failed
UnsatisfiableError: The following specifications were found to be incompatible with each other:
Output in format: Requested package -> Available versions
conda-forgeから導入
conda-forgeとopen3d-adminを同時に指定すると導入に成功する。
-cはチャンネル(=レポジトリ名)。
open3d 0.15では、チャンネルをconda-forgeとopen3d-admin、両方とも指定しなければ失敗する様子。
問題と今後の予想
この方法で導入した場合、open3dを使用したスクリプトを実行するたびに以下のWarningが出てしまう。
2022年6月時点で、condaサポートがRequestされているので、多分、、、多分公式が折れてくれるのではないか。
環境変数を設定したPowerShellをbatから起動
PowerShellを使いたい。環境変数を都度設定するのが面倒なのでスクリプトファイルにまとめるのだが、そのままでは権限不足で実行できない。そこでbatを作りcmdを走らせ、中から権限付与したpowershellを起動。起動時に実行させたいスクリプトを書いたps1ファイルを与えて実行する。
callps.bat
@rem SJISで保存しないとコメントが文字化けする @rem noexit poweshell を閉じない @rem ExecutionPolicy 権限を変更 @rem .\path.ps1 powershell のスクリプトを実行 powershell -noexit -ExecutionPolicy Unrestricted .\path.ps1
path.ps1
# 権限がちゃんと変更されているかを確認表示 Get-ExecutionPolicy # 使いたいアプリケーションのパスを追加 $ENV:Path+=";C:\apps\7z2201-extra" $ENV:Path+=";C:\apps\sakuraeditor" $ENV:Path+=";C:\apps\ImageMagick-7.1.0-portable-Q16-x64" cd C:\Software\command\work
使い方
上記.bat , ps1ファイルを同じ場所へ置き、callps.batをダブルクリックなりすると設定したPowerShellが起動する。
VTKでPointCloud表示
VTKでPointCloudを表示する方法。VTKにはPointCloud型というものがなく、PolyDataで点群も表すようになっている。元となったコードがPythonだったのでそれをC++に書き換えた格好になる。
元コード(Python)
https://stackoverflow.com/questions/7591204/how-to-display-point-cloud-in-vtk-in-different-colors
VTK_PointCloud.hpp
#pragma once // https://stackoverflow.com/questions/7591204/how-to-display-point-cloud-in-vtk-in-different-colors #include <vtkRenderer.h> #include <vtkSmartPointer.h> #include <vtkPolyData.h> //vtkPolyData用 #include <vtkPolyDataMapper.h> #include <vtkPointData.h> // 頂点データ用 #include <vtkUnsignedCharArray.h> //色データ用 #include <vtkProperty.h> //#include <vtkPoints.h> //#include <vtkPolygon.h> class VtkPointCloud { public: vtkSmartPointer<vtkPolyData> _polydata; vtkSmartPointer<vtkPolyDataMapper> _mapper; vtkSmartPointer<vtkActor> _actor; vtkSmartPointer < vtkPoints > _points; vtkSmartPointer < vtkCellArray > _cells; vtkSmartPointer < vtkUnsignedCharArray > _colors; VtkPointCloud(double zMin = -10.0, double zMax = 10.0, int maxNumPoints = 1e6) { _polydata = vtkSmartPointer<vtkPolyData>::New(); clearPoints(); _mapper = vtkSmartPointer<vtkPolyDataMapper>::New(); _mapper->SetInputData(_polydata); _mapper->SetColorModeToDefault(); //_mapper->SetScalarRange(zMin, zMax); _mapper->SetScalarVisibility(1); _actor = vtkSmartPointer<vtkActor>::New(); _actor->SetMapper(_mapper); } void addPoint(double point[3], unsigned char color[3]) { vtkIdType pointId = _points->InsertNextPoint(point); _cells->InsertNextCell(1); _cells->InsertCellPoint(pointId); _colors->InsertNextTuple3(color[0], color[1], color[2]); } void clearPoints() { _points = vtkSmartPointer < vtkPoints >::New(); _cells = vtkSmartPointer < vtkCellArray>::New(); //////////////////////////////////// _colors = vtkSmartPointer<vtkUnsignedCharArray>::New(); _colors->SetNumberOfComponents(3); _colors->SetName("Colors"); _polydata->GetPointData()->SetScalars(_colors); _polydata->GetPointData()->SetActiveScalars("Colors"); //////////////////////////////////// _polydata->SetPoints(_points); _polydata->SetVerts(_cells); } };
main.cpp
#pragma once #include "VTK_PointCloud.hpp" // VTK_MODULE_INITに必要 #include <vtkAutoInit.h> #include <vtkRenderer.h> #include <vtkRenderWindow.h> #include <vtkWin32RenderWindowInteractor.h> //win32api対応 #include <vtkInteractorStyleImage.h> //////////////////////////////////////////////////////// #pragma comment(lib,"vtkCommonCore-9.1.lib") #pragma comment(lib,"vtkRenderingCore-9.1.lib") #pragma comment(lib,"vtkInteractionStyle-9.1.lib") #pragma comment(lib,"vtkCommonDataModel-9.1.lib ") // ポリゴン用 #pragma comment(lib,"vtkRenderingOpenGL2-9.1.lib") //必須 VTK_MODULE_INIT(vtkRenderingOpenGL2); VTK_MODULE_INIT(vtkInteractionStyle); int main(int argc, char** argv) {
// 点群生成
auto ptc = std::make_unique< VtkPointCloud>(); for (size_t i = 0; i < 100000; i++) { double x = (double)rand() / (double)RAND_MAX; double y = (double)rand() / (double)RAND_MAX; double z = (double)rand() / (double)RAND_MAX; ptc->addPoint( std::array<double, 3>{ x, y, z }.data(), std::array<unsigned char, 3>{ (unsigned char)(x * 255), (unsigned char)(y * 255), (unsigned char)(z * 255)}.data() ); } // 頂点サイズを指定する場合 // #include <vtkProperty.h> ptc->_actor->GetProperty()->SetPointSize(3); ////////////////////////////////////////////////////////////////// ////////////////////////////////////////////////////////////////// ////////////////////////////////////////////////////////////////// ////////////////////////////////////////////////////////////////// vtkSmartPointer<vtkRenderer> renderer = vtkSmartPointer<vtkRenderer>::New(); renderer->AddActor(ptc->_actor); renderer->ResetCamera(); ////////////////////////////////////// auto interactor = vtkSmartPointer<vtkRenderWindowInteractor>::New(); vtkSmartPointer<vtkInteractorStyleTrackballCamera> style = vtkSmartPointer<vtkInteractorStyleTrackballCamera>::New(); interactor->SetInteractorStyle(style); ////////////////////////////////////// auto renderWindow = vtkSmartPointer<vtkRenderWindow>::New(); renderWindow->AddRenderer(renderer); renderWindow->SetInteractor(interactor); renderWindow->Render(); interactor->Start(); //イベントループへ入る return 0; }
Ubuntu + g++ + Python/C APIでPythonからCを呼び出す
ずっとWindowsでやってきたので今度はUbuntuで同じことをする。
Ubuntuの場合はdllではなくsoファイルという事になるが、手順などは変わらない。
必要なファイルのパスを見つける
sysconfig.get_config_varsで各パスを見つける。.aはwindowsの.libに該当。
一覧を出すと長いので引数に値名を入れて必要なものだけ見つける
# where-is-pyh.py import sysconfig import pprint pprint.pprint(sysconfig.get_config_vars('LIBDIR')) # .a ファイルの場所 pprint.pprint(sysconfig.get_config_vars('LIBRARY')) # .a ファイルの名前 pprint.pprint(sysconfig.get_config_vars('INCLUDEPY')) # python.h の場所
['/home/myname/anaconda3/envs/BindTest/lib']
['libpython3.9.a']
C++のプログラムを書く
Windows版と動的リンクライブラリの設定が若干違う(というかない)が基本的には同じ。DllMainなどは不要なのでその分コードは短い。
mymod.hpp
// mymod.hpp // このプロジェクトのビルド結果を「sopy.so」とする。 #include <Python.h> // この関数をPython側から呼び出したいとする。 PyObject * hello_in_c(PyObject*); // 第一引数はPython側のself用。 // 関数へアクセスする方法一覧 static PyMethodDef method_list[] = { // Pythonで使用する関数名 , C++内で使用する関数名 , 引数の個数に関するフラグ , docstring { "hello_on_python", (PyCFunction)hello_in_c, METH_VARARGS , nullptr }, // ... 公開したい関数の個数分だけ記述する // 配列の最後は全てNULLの要素を入れておく { nullptr, nullptr, 0, nullptr } }; // モジュールを定義する構造体 static PyModuleDef module_def = { PyModuleDef_HEAD_INIT, "sopy", // モジュール名 "Example of pyhton wrapper", // モジュール説明 0, method_list // Structure that defines the methods of the module }; // 関数名はPyInit_ + soファイル名 PyMODINIT_FUNC PyInit_sopy() { return PyModule_Create(&module_def); }
mymod.cpp
// mymod.cpp #include "mymod.hpp" PyObject* hello_in_c(PyObject*) { printf("hello world from C"); return Py_None; }
ビルド
最初のステップでsysconfigで見つけたパスとライブラリ名をそれぞれ指定する。
$ g++ mymod.cpp -shared -fPIC -o sopy.so -I/home/myname/anaconda3/envs/BindTest/include/python3.9 -L/home/myname/anaconda3/envs/BindTest/lib -lpython3.9
テスト
import sopy sopy.hello_on_python()
Windows + VC++ + Python/C APIでPythonからCを呼び出す(6)PythonのリストをC++へ渡す
Python側からリストを渡したときの受け取り方。
mymod.cpp
// mymod.cpp #include "mymod.hpp" void print_int(PyObject* p); void print_float(PyObject* p); void print_string(PyObject* p); PyObject* list_in_c(PyObject*, PyObject* args) { // 受け取ったリストの内容をlistargsへ入れる PyObject* listargs; if (!PyArg_ParseTuple(args, "O!", &PyList_Type, &listargs)) return NULL; // リストの要素数を取得 int count = PyList_Size(listargs); printf("list item count == %d\n", count); // リストのアイテムを取得 PyObject* val_0 = PyList_GetItem(listargs, 0); PyObject* val_1 = PyList_GetItem(listargs, 1); PyObject* val_2 = PyList_GetItem(listargs, 2); //各要素の型は、PyObject*を _Check 関数にかけて型チェックを行う ////////////////////////////// if ((bool)PyLong_Check(val_0) == true) { print_int(val_0); } else if ((bool)PyFloat_Check(val_0) == true) { print_float(val_0); } else if ((bool)PyUnicode_Check(val_0) == true) { print_string(val_0); } ////////////////////////////// if ((bool)PyLong_Check(val_1) == true) { print_int(val_1); } else if ((bool)PyFloat_Check(val_1) == true) { print_float(val_1); } else if ((bool)PyUnicode_Check(val_1) == true) { print_string(val_1); } ////////////////////////////// if ((bool)PyLong_Check(val_2) == true) { print_int(val_2); } else if ((bool)PyFloat_Check(val_2) == true) { print_float(val_2); } else if ((bool)PyUnicode_Check(val_2) == true) { print_string(val_2); } } void print_int(PyObject* p) { long v = PyLong_AsLong(p); printf("%d\n", v); } void print_float(PyObject* p) { float v = PyFloat_AsDouble(p); printf("%lf\n", v); } void print_string(PyObject* p) { const char* v = PyUnicode_AsUTF8(p); printf("%s\n", v); }
mymod.hpp 抜粋
__declspec(dllexport) extern "C" PyObject * list_in_c(PyObject*, PyObject*); // 関数へアクセスする方法一覧 static PyMethodDef method_list[] = { // Pythonで使用する関数名 , C++内で使用する関数名 , 引数の個数に関するフラグ , docstring { "list_function", (PyCFunction)list_in_c, METH_VARARGS , nullptr }, // 配列の最後は全てNULLの要素を入れておく { nullptr, nullptr, 0, nullptr } };
Pythonスクリプト
import DLLforPython DLLforPython.list_function([22,"abc",12.3])
実行結果
22
abc
12.300000
Windows + VC++ + Python/C APIでPythonからCを呼び出す(5)CのポインタをPythonへ渡す
ポインタを渡す場合はPyCapsule_Newで包んで渡す。
データがnewされたものなら、一緒にdeleterも渡すことができる。
mymod.hpp 変更
// C++側の関数宣言 // 配列作成 __declspec(dllexport) extern "C" PyObject * create_array_in_c(PyObject*); // 配列からアイテム取得 __declspec(dllexport) extern "C" PyObject * get_item_in_c(PyObject*, PyObject* args); // 関数へアクセスする方法一覧 static PyMethodDef method_list[] = { { "create_array", (PyCFunction)create_array_in_c, METH_VARARGS , nullptr }, { "get_item", (PyCFunction)get_item_in_c, METH_VARARGS , nullptr }, // 配列の最後は全てNULLの要素を入れておく { nullptr, nullptr, 0, nullptr } };
mymod.cpp
// mymod.cpp #include "mymod.hpp" #define NAME nullptr // デリータ void array_deleter(PyObject* obj) { long* p = (long*)PyCapsule_GetPointer(obj, NAME); delete [] p; } // データを作成する関数 PyObject* create_array_in_c(PyObject*) { long* p = new long[5]{ 0,1,2,3,4 }; // ポインタをPyObjectへ変換 // 同時にデリータを指定して自動解放を可能にする PyObject* pyo = PyCapsule_New(p, NAME, array_deleter); return pyo; } PyObject * get_item_in_c(PyObject*, PyObject * args) { PyObject* dataptr; int index; // argsから引数取り出し // PyObject* は 'O' を使用 if (!PyArg_ParseTuple(args, "Oi", &dataptr, &index)) return NULL; long* p = (long*)PyCapsule_GetPointer(dataptr, NAME); return PyLong_FromLong(p[index]); }
test.py
import DLLforPython array = DLLforPython.create_array() print( DLLforPython.get_item(array,3) )
Windows + VC++ + Python/C APIでPythonからCを呼び出す(4)Cへ複数の引数を渡す
Python/C APIでは引数を複数渡す場合、第二引数にPython側から渡された引数がすべてまとめられている。それを取り出すためにPyArg_ParseTupleを使うのだが、この時何番目の引数の型が何かを関数へ教えてやる必要がある。
下の例では、それが第二引数の"ii"となっている。
簡単な例
mymod.hpp
// mymod.hpp
#pragma once #include <Python.h> #pragma comment (lib,"python39.lib")
// C++側の関数宣言 // python側から引数が複数与えられる場合、 // 第二引数に全ての引数がまとめて入っている __declspec(dllexport) extern "C" PyObject * add_in_c(PyObject*, PyObject* xy);
// 関数へアクセスする方法一覧 static PyMethodDef method_list[] = { // Pythonで使用する関数名 , C++内で使用する関数名 , 引数の個数に関するフラグ , docstring { "add", (PyCFunction)add_in_c, METH_VARARGS , nullptr }, // 配列の最後は全てNULLの要素を入れておく { nullptr, nullptr, 0, nullptr } };
// モジュールを定義する構造体 static PyModuleDef module_def = { PyModuleDef_HEAD_INIT, "DLLforPython", // モジュール名 "Example of pyhton wrapper", // モジュール説明 0, method_list // Structure that defines the methods of the module }; PyMODINIT_FUNC PyInit_DLLforPython() { return PyModule_Create(&module_def); }
mymod.cpp
// mymod.cpp #include "mymod.hpp" PyObject* add_in_c(PyObject*, PyObject* xy) { long a, b;
// 引数xyからPython側から渡された二つの引数を取り出す // 第二引数の "ii" はaがint,bがintを表す int ret = PyArg_ParseTuple(xy, "ii", &a, &b); if (!ret) return NULL; return PyLong_FromLong(a + b); }
test.py
import DLLforPython print( DLLforPython.add(2,3) )
PyArg_ParseTuple の第二引数について
データ型によってどのような指定を行うかは以下に書かれている。
https://docs.python.org/ja/3/c-api/arg.html
mymod.hpp 変更
// C++側の関数宣言 // python側から引数が複数与えられる場合、 // 第二引数に全ての引数がまとめて入っている __declspec(dllexport) extern "C" PyObject * function_in_c(PyObject*, PyObject* xy); // 関数へアクセスする方法一覧 static PyMethodDef method_list[] = { // Pythonで使用する関数名 , C++内で使用する関数名 , 引数の個数に関するフラグ , docstring { "function", (PyCFunction)function_in_c, METH_VARARGS , nullptr }, // 配列の最後は全てNULLの要素を入れておく { nullptr, nullptr, 0, nullptr } };
mymod.cpp
// mymod.cpp #include "mymod.hpp" PyObject* function_in_c(PyObject*, PyObject* args) { bool b; // PyArg_ParseTupleには b を与える char *s; // PyArg_ParseTupleには s を与える long i; // PyArg_ParseTupleには i を与える float f; // PyArg_ParseTupleには f を与える Py_complex d;// PyArg_ParseTupleには D を与える // 第三引数以降は可変長引数 int ret = PyArg_ParseTuple( args, "bsifD", &b, &s, &i, &f, &d ); printf("bool %s\n", b ? "true" : "false"); printf("char %s\n", s); printf("long %d\n", i); printf("float %lf\n", f); printf("complex %lf+i%lf\n", d.real, d.imag); return Py_None; }
test.py
import DLLforPython DLLforPython.function( True, "hello", 5, 4.8, 3+2j )
char hello
long 5
float 4.800000
complex 3.000000+i2.000000
Windows + VC++ + Python/C APIでPythonからCを呼び出す(3)Cから値を返す
mymod.h
#pragma once #include <Python.h> // libファイルが必要 // anaconda3\Include にPython.hがある時、おそらく // anaconda3\libs にある。 #pragma comment (lib,"python39.lib")
// C++側の関数宣言 __declspec(dllexport) extern "C" PyObject * get_int_in_c(PyObject*); __declspec(dllexport) extern "C" PyObject * get_bool_in_c(PyObject*); __declspec(dllexport) extern "C" PyObject * get_float_in_c(PyObject*); __declspec(dllexport) extern "C" PyObject * get_string_in_c(PyObject*);
// 関数へアクセスする方法一覧 static PyMethodDef method_list[] = { // Pythonで使用する関数名 , C++内で使用する関数名 , 引数の個数に関するフラグ , docstring { "get_int", (PyCFunction)get_int_in_c, METH_VARARGS , nullptr }, { "get_bool", (PyCFunction)get_bool_in_c, METH_VARARGS , nullptr }, { "get_float", (PyCFunction)get_float_in_c, METH_VARARGS , nullptr }, { "get_string", (PyCFunction)get_string_in_c, METH_VARARGS , nullptr }, // 配列の最後は全てNULLの要素を入れておく { nullptr, nullptr, 0, nullptr } };
// モジュールを定義する構造体 static PyModuleDef module_def = { PyModuleDef_HEAD_INIT, "DLLforPython", // モジュール名 "Example of pyhton wrapper", // モジュール説明 0, method_list // Structure that defines the methods of the module }; PyMODINIT_FUNC PyInit_DLLforPython() { return PyModule_Create(&module_def); }
mymod.cpp
// mymod.cpp #include "mymod.hpp"
// intを返す PyObject* get_int_in_c(PyObject*) { PyObject* obj = PyLong_FromLong(100); return obj; }
// boolを返す PyObject* get_bool_in_c(PyObject*) { PyObject* obj = PyBool_FromLong((long)false); return obj; }
// floatを返す PyObject * get_float_in_c(PyObject*) { PyObject* obj = PyFloat_FromDouble(3.5); return obj; }
// stringを返す PyObject * get_string_in_c(PyObject*) { PyObject* obj = PyUnicode_FromFormat("test"); return obj; }
test.py
import DLLforPython print( DLLforPython.get_int() ) print( DLLforPython.get_bool() ) print( DLLforPython.get_float() ) print( DLLforPython.get_string() )
False
3.5
test