月火水木金土日
icuライブラリで文字列を書記素単位で分割(ubrk_open)
以前、UnicodeStringを使用したが、これは内部に文字列をコピーしてしまうので、文字列の管理をicuにやらせないのであれば効率が悪い。ubrk_openでブレークイテレータを取得すると、元の文字列に対して操作できる。
#include <iostream> #include <unicode/ubrk.h> #include <unicode/ustring.h> #include <vector> #include <fstream> // 要リンク #pragma comment(lib, "icuuc.lib") struct Grapheme { int32_t start; int32_t end; };
std::vector<Grapheme> createGraphemeList(const char16_t* text,const size_t length) { UErrorCode status = U_ZERO_ERROR; std::vector<Grapheme> graphemes; // イテレータ作成 UBreakIterator* bi = ubrk_open(UBRK_CHARACTER, "ja_JP", nullptr, 0, &status); if (U_FAILURE(status)) { return std::vector<Grapheme>(); // エラーが発生 } // テキストを設定 ubrk_setText(bi, (const UChar*)text, length, &status); // ubrk_setText(bi, (const UChar*)text, -1, &status);// null終端の場合は -1 を指定できる if (U_FAILURE(status)) { ubrk_close(bi); return std::vector<Grapheme>(); // エラーが発生 } // 最初の書記素の位置を取得 int32_t start = ubrk_first(bi); int32_t end; // 書記素リストを作成 while ((end = ubrk_next(bi)) != UBRK_DONE) { graphemes.push_back(Grapheme{ start, end }); start = end; } // 終了処理 ubrk_close(bi); return graphemes; }
int main() { // 日本語ロケール setlocale(LC_ALL, "japanese"); std::u16string u16str = u"あいうえお"; std::vector<Grapheme> glist = createGraphemeList(u16str.data(),u16str.length()); for(size_t i = 0; i < glist.size(); i++) { size_t length = glist[i].end - glist[i].start; std::wstring u16w( (wchar_t*)u16str.data()+ glist[i].start, length); std::wcout << u16w;// 一文字ずつ表示 std::wcout << "( " << glist[i].start << L" " << glist[i].end << " )" << std::endl; } }
結合文字の確認
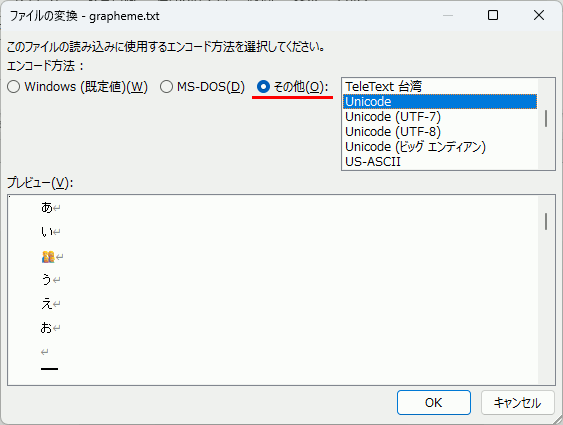
結合文字はWindowsのコンソールで扱うとうまく表示できないので、代わりにテキストファイルとして出力して動作確認する。
int main() { // 日本語ロケール setlocale(LC_ALL, "japanese"); std::u16string u16str = u"あい👨👩👧👦うえお"; // 👨👩👧👦 絵文字(結合文字) std::vector<Grapheme> glist = createGraphemeList(u16str.data(), u16str.length()); // バイナリ出力 std::ofstream out("grapheme.txt", std::ios_base::binary); for (size_t i = 0; i < glist.size(); i++) { size_t length = glist[i].end - glist[i].start; out.write((const char*)(u16str.data() + glist[i].start), length * 2);// 一文字出力 out.write("\n", 2); } }
確認には、Wordを開き、テキストファイルを開く際の文字コードをUnicodeに指定するのが良い。