月火水木金土日
CUDAのバンクコンフリクトを再現・検出してみる
バンクコンフリクトは、CUDAでシェアードメモリを使ったときに生じることがある。
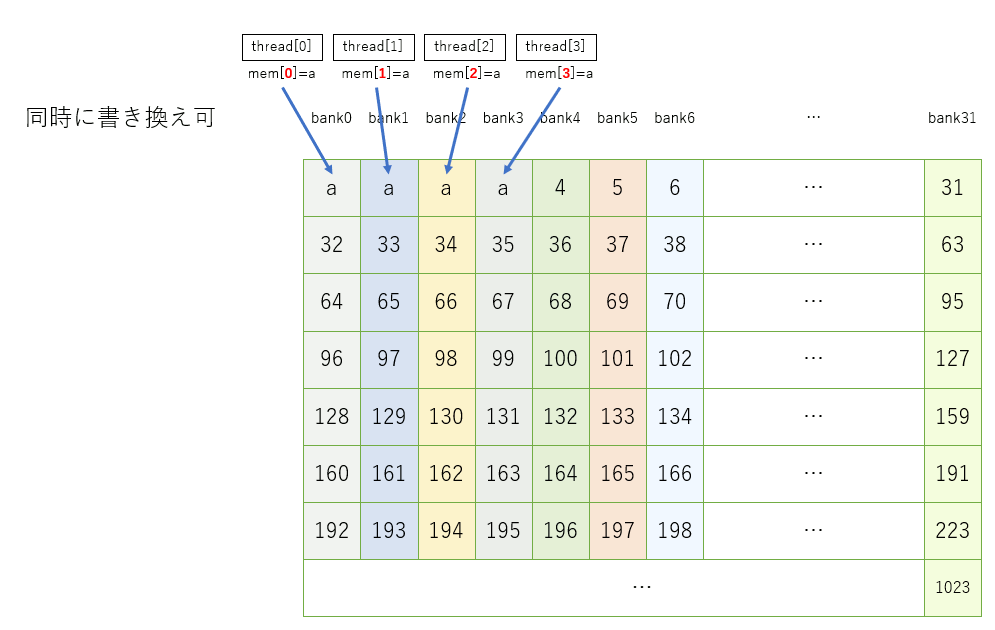
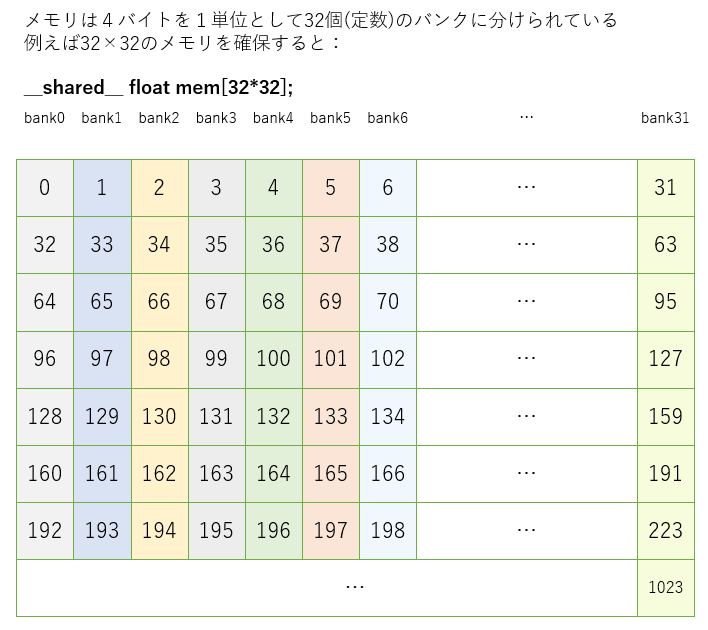
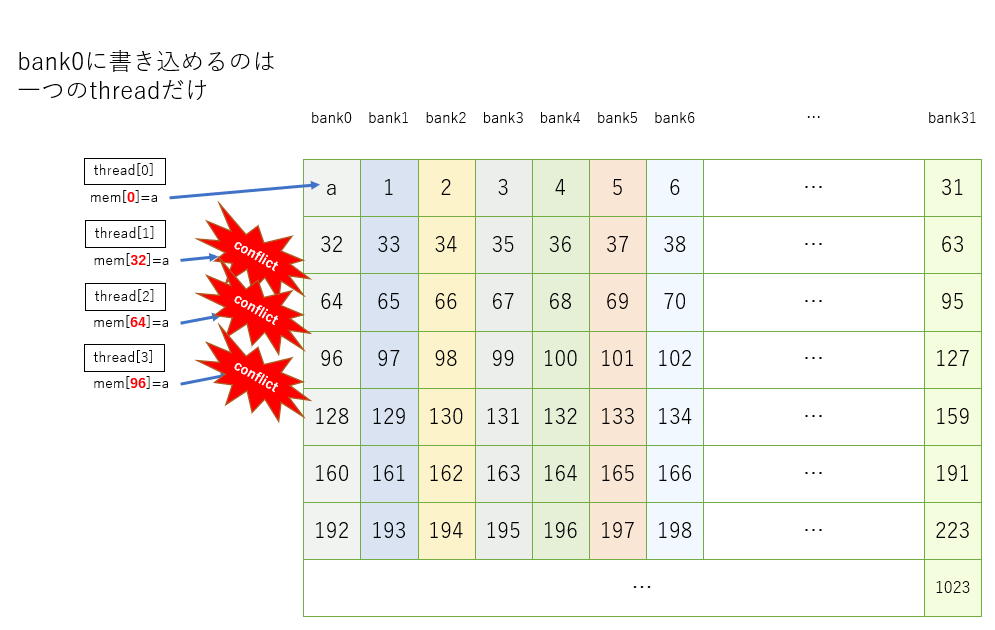
CUDAはシェアードメモリを32個のバンクという単位で分割管理していて、違うスレッドが同じバンクに同時にアクセスできない。
floatの配列で例えると、mem[0],mem[1],mem[2]は全て違うバンクに属するが、mem[0],mem[32],mem[64]は全て同じバンクに属する。
なおバンク数はGPUによって異なる。
バンクコンフリクトを再現するコード
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> #include <stdlib.h> /////////////////////////////////////////////// // GPU側 //////////////////////////////////////
// 32個のスレッドで一回ずつ呼び出される。 __global__ void test_kernel(unsigned int* c) { // 32 × 32 のシェアードメモリ確保 // この時、 mem[0] , mem[32] , mem[64] , ... を同時にアクセスするとバンクコンフリクトする __shared__ float mem[32*32]; //このスレッドの番号を取得 size_t xpos = blockIdx.x * blockDim.x + threadIdx.x; // シェアードメモリに書き込み xposが0,1,2,3...なので、0,32,64,...(=同じバンク)に書き込む mem[xpos*32] = xpos; // これを入れないと最適化?されるのか検出できない c[xpos] = mem[xpos]; }
//////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////// int main() { dim3 grid(1, 1); //グリッド数 dim3 block(32, 1); //ブロック数 unsigned int* p_gpu; cudaMalloc( (void**)&p_gpu,32*4); test_kernel << <grid, block >> > (p_gpu); // 32個のスレッドを実行 unsigned int p_cpu[32]; cudaMemcpy(&p_cpu, p_gpu, 32*4, cudaMemcpyDeviceToHost);//GPU側から実行結果を取得 cudaFree(p_gpu);//GPU側のメモリを解放 for (size_t i = 0; i < 32; i++) printf("%d\n", p_cpu[i]); return 0; }
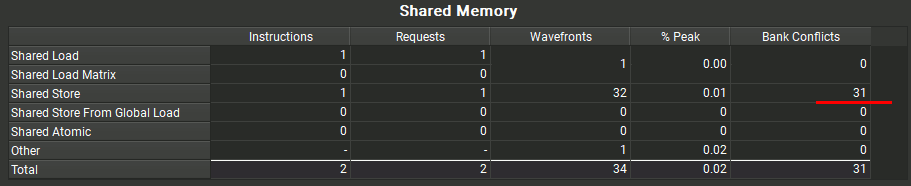
このプログラムは各スレッドが0,32,64,96,...の要素にアクセスしようとするが、すべて同じバンクの要素なため、同時に書き換えることができず、遅延が発生する。
バンクコンフリクトがないコード
カーネルのmemに書き込む部分を変更する。
// 32個のスレッドで一回ずつ呼び出される。 __global__ void test_kernel(unsigned int* c) { // 32 × 32 のメモリ // この時、 mem[0] , mem[32] , mem[64] , ... を同時にアクセスするとバンクコンフリクトする __shared__ float mem[32*32]; //アクセス法 //このスレッドが担当する画素の位置を二次元座標で求める size_t xpos = blockIdx.x * blockDim.x + threadIdx.x; // シェアードメモリに書き込み xposが0,1,2,3,... なので、違うバンクに書き込む mem[xpos] = xpos; // これを入れないと最適化?されるのか検出できない c[xpos] = mem[xpos]; }