連番ファイル名の番号をシフトするpythonスクリプト
import os import random, string
# @brief ダミーファイル名を作成 # @details 処理時、一度この名前でファイルを書き換えてから目的の名前に変更する # @sa https://qiita.com/Scstechr/items/c3b2eb291f7c5b81902a def create_random_filename(): n = 10 dummy = '' while True: dummy = ''.join(random.choices(string.ascii_letters + string.digits, k=n)) # 生成した文字列をファイル名とするファイルが存在しなければ処理を終了 if os.path.exists(dummy) == False: break return dummy
# @brief ファイル名の変更規則一覧作成 # @param [in] _format_ ファイル名の書式 # @param [in] _range_ 元のファイルの番号の範囲 # @param [in] _new_offset_ 新しい番号の先頭番号 # @return [ 現在のファイル名 , ダミーファイル名 , 変更後のファイル名 ] のリスト def sequence_filename( _format_ , _range_, _new_offset_ ): Li=[] dir = os.path.dirname( _format_ ) + "/" for i in _range_: # 変更したい対象のファイル名を作成 fname = _format_ % i retfname = _format_ % (_new_offset_ + i - _range_[0])# 新たなファイル名を作成 # ランダムなファイル名作成 dummyname = dir + create_random_filename() Li.append([fname,dummyname,retfname]) return Li
def filename_shift( _format_ , _start_,_stop_, _new_offset_): Li = sequence_filename( _format_ , range(_start_,_stop_+1), _new_offset_ ) # 現在のファイル名 → ダミーファイル名 for j in Li: os.rename(j[0],j[1]) # ダミーファイル名 → 目的のファイル名 for j in Li: os.rename(j[1],j[2])
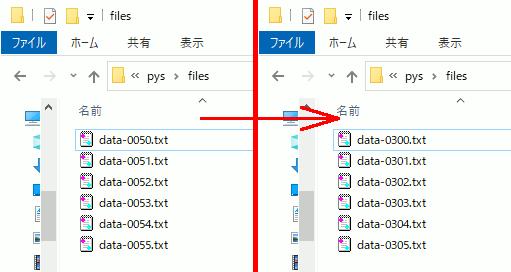
############################################ ############################################ ############################################ # 50番~のファイル名を300番~に変更 filename_shift( "files/data-%04d.txt" , 50,55,300 )
Windowsのゴミ箱にあまりにも大量のファイルを入れすぎて迂闊に表示もできなくなった場合の対応
状況
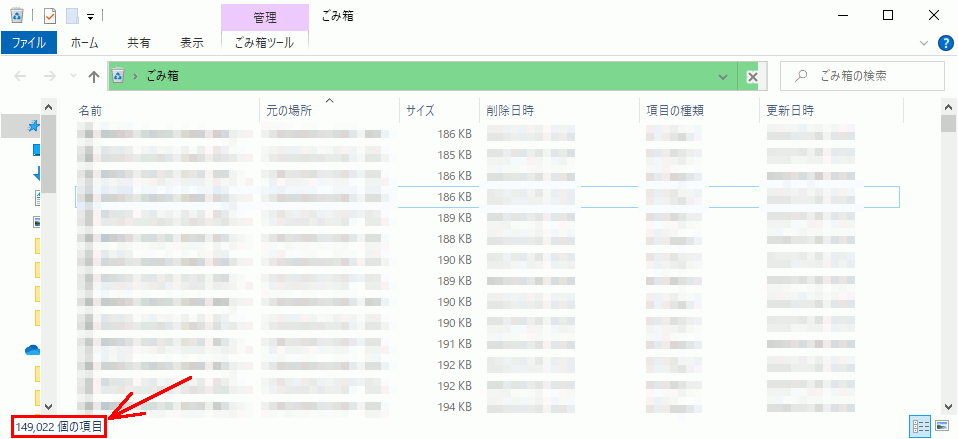
ファイルを捨てすぎて、ゴミ箱を開くのすら数分~数十分かかるような場合。
下手にゴミ箱から直接ファイルを削除しようものならOSごとフリーズする(復帰不可)。
しかもフリーズしたからと電源を落とすと「起動ドライブが見つかりません」のようなメッセージが出てドライブが認識できなくなる(電源落としてしばらく放置で解消を確認)
という事態に職場のPCで(←重要)陥り、とりあえず確実に安全と言えそうな手段を模索している。
なお上記図では149,022個の項目とあるが、これでもだいぶ減らした。
目的
1.ゴミ箱を再び使えるようにする。
2.ゴミ箱に圧迫されているドライブの領域を解放する
3.安全に対処する。上記1,2を満たす限り、安全でさえあれば他はどうでもいい。
手順
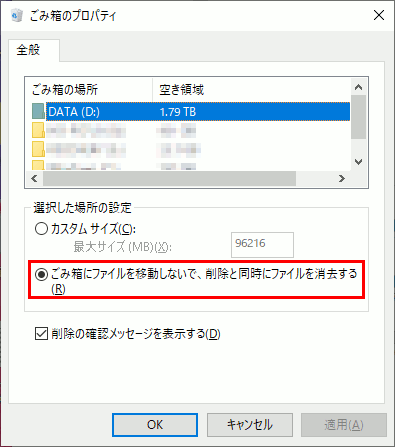
1.ファイルをゴミ箱に入れずに削除する設定にする
必須ではないが、Shiftを押しながら削除では押し忘れてゴミ箱に逆戻りしてしまう可能性があるので設定を変更しておいた方が無難。
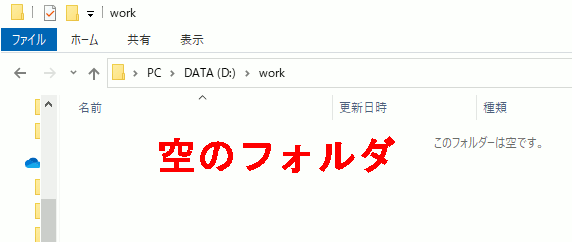
2.別の空フォルダを用意
3.ゴミ箱を開き、ファイル一覧が表示された時点で読み込みを中断する

ゴミ箱の中身のファイル一覧は全て読み込まれなくてもある程度で一覧表示がされる。完全に終わらせようと待っているとそれだけでフリーズする。とりあえず一覧が出てファイルが多少なりとも見えた時点で読み込みを中止する。
4.先に用意した空フォルダへゴミ箱のファイルを数千件だけ移動
私の環境を基準に言えば、一度に5000件以上はやらない方がいい。
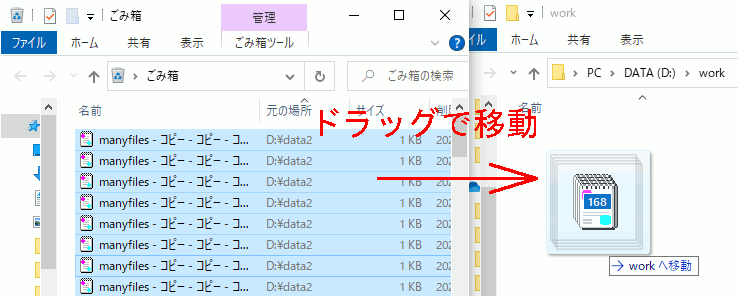
5.フォルダごと削除
ゴミ箱に移動せずに削除する設定をしていない場合、Shiftキーを押しながら削除する。

6.2~4を繰り返す
感想
1.このトラブルは、「一つのフォルダの中に」ファイルが大量に入っていると処理が異常に重くなるらしいことが恐らくは重要である。
2.なお今回のゴミ箱はDドライブの物だったのだが、作業中どんどんCドライブの空き容量が減っていったので、恐らくはページファイルが作成されている。フリーズの原因か。
3.そういえばリストボックスは項目数が多くなると挙動が非常に重くなるので、扱う件数が非常に多いことが想定される場合はオーナードローリストボックスを使えとWindowsプログラミングでは言われている。
4.右クリックで「ごみ箱を空にする」ではどうなのか。怖くて試していない。
cudaMalloc/cudaFreeをcuda DLLの外側から呼び出す
mallocしたメモリはfreeするまで解放されない。それは知っている。
知っているが、CUDAプログラムをdll化した場合、まさかdll内関数から出た瞬間に自動解放されたりしないだろうな・・・?
という不安が頭をよぎったのでテスト。
以下、gpu_my_allocやdevice_to_hostなどは全てcuファイル内に書かれている。
C++側から別個に呼び出してもちゃんと動作するらしい。
C++側
#include <iostream> #pragma warning(disable:4996) #include "../CudaRuntime1/mytest.h" #pragma comment(lib,"CudaRuntime1.lib") void pnmP3_Write(const char* const fname, const int vmax, const int width, const int height, const unsigned char* const p); int main() { data_t dat; dat.width = 100; dat.height = 50; unsigned char *c = new unsigned char[dat.width * dat.height * 3]; for (size_t i = 0; i < dat.width * dat.height; i++) { c[i * 3 + 0] = 0; c[i * 3 + 1] = 0; c[i * 3 + 2] = 255; } dat.rgbdata = c; //GPU側メモリ確保 void* device = gpu_my_alloc(dat.width, dat.height); //GPU側へデータ転送 host_to_device(&dat, device); //処理実行 func_inverse(dat.width, dat.height, device); //CPU側へ結果を返却 device_to_host(device, &dat); //GPU側のメモリ解放 gpu_my_free(device); pnmP3_Write("test.ppm", 255, dat.width, dat.height, dat.rgbdata); } ///////////////////////////////////////////// //画像ファイル書き出し///////////////////////// //! @brief PPM(RGB各1byte,カラー,テキスト)を書き込む //! @param [in] fname ファイル名 //! @param [in] vmax 全てのRGBの中の最大値 //! @param [in] width 画像の幅 //! @param [in] height 画像の高さ //! @param [in] p 画像のメモリへのアドレス //! @details RGBRGBRGB....のメモリを渡すと、RGBテキストでファイル名fnameで書き込む void pnmP3_Write(const char* const fname, const int vmax, const int width, const int height, const unsigned char* const p) { // PPM ASCII FILE* fp = fopen(fname, "wb"); fprintf(fp, "P3\n%d %d\n%d\n", width, height, vmax); size_t k = 0; for (size_t i = 0; i < (size_t)height; i++) { for (size_t j = 0; j < (size_t)width; j++) { fprintf(fp, "%d %d %d ", p[k * 3 + 0], p[k * 3 + 1], p[k * 3 + 2]); k++; } fprintf(fp, "\n"); } fclose(fp); }
CUDA側
mytest.h
#ifdef __DLL_EXPORT_DO #define DLL_PORT extern "C" _declspec(dllexport) #else #define DLL_PORT extern "C" _declspec(dllimport) #endif struct data_t { int width; int height; unsigned char* rgbdata; }; //GPU側メモリ確保 DLL_PORT void* gpu_my_alloc(int width, int height); //処理実行 DLL_PORT void func_inverse(int width,int height, void* device); //GPU側へデータ転送 DLL_PORT void host_to_device(data_t* host, void* device); //CPU側へ結果を返却 DLL_PORT void device_to_host(void* device, data_t* host); //GPU側のメモリ解放 DLL_PORT void gpu_my_free(void* gpuptr);
mytest.cu
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> #include "mytest.h" struct gpudata { int width; int height; unsigned char* c; }; __device__ void color_inverse(unsigned char* c, int width, int height) { c[0] = 255 - c[0]; c[1] = 255 - c[1]; c[2] = 255 - c[2]; } __global__ void thread_inverse(gpudata data) { //このスレッドが担当する画素の位置を二次元座標で求める size_t xpos = blockIdx.x * blockDim.x + threadIdx.x; size_t ypos = blockIdx.y * blockDim.y + threadIdx.y; if (xpos < data.width && ypos < data.height) { size_t pos = (ypos * data.width + xpos) * 3; unsigned char* c = data.c + pos; // この関数はfunction.cuで定義されている color_inverse(c, xpos, ypos); } } void func_inverse(int width, int height, void* device){ // 16*16 == 256 < 512 int blockw = 16; int blockh = 16; dim3 block(blockw, blockh); int gridw = width / blockw + 1; int gridh = height / blockh + 1; dim3 grid(gridw,gridh); gpudata gpud; gpud.width = width; gpud.height = height; gpud.c = (unsigned char*)device; thread_inverse<<<grid,block>>> (gpud);//GPU側の関数を呼出 } void host_to_device(data_t* host, void* device) { cudaMemcpy( device, host->rgbdata, host->width * host->height * 3, cudaMemcpyHostToDevice);//GPU側へ処理したいデータを転送 } void device_to_host(void* device, data_t* host) { cudaMemcpy( host->rgbdata, device, host->width * host->height * 3, cudaMemcpyDeviceToHost);//GPU側から実行結果を取得 } void* gpu_my_alloc(int width, int height) { unsigned char* g_gpu; cudaMalloc( (void**)&g_gpu, width * height * 3);//GPU側メモリ確保 return g_gpu; } void gpu_my_free(void* gpuptr) { cudaFree(gpuptr);//GPU側のメモリを解放 }
GLFW3でタイマー(と同じ事)を使う
glfw3にはタイマー、つまり指定した時間が経ったら呼び出されるコールバック関数を指定するような機能が無い。従ってループ内でglfwGetTime()関数で現在時刻を秒単位で取得し、前回時刻取得時から目的の秒数だけ経ったら処理を実行することでタイマーと同じ効果を出す。
#include <cstdlib> #include <iostream> #include <Windows.h> #include <gl/GL.h> #include <GLFW/glfw3.h> #pragma comment(lib,"opengl32.lib") #pragma comment(lib,"glfw3.lib") int main() { //////////////////////////////////////////////////////////////////////////////// // GLFW の初期化 if (glfwInit() == GL_FALSE) { // 初期化に失敗したら終了 return 1; } //////////////////////////////////////////////////////////////////////////////// // ウィンドウを作成 GLFWwindow* window = glfwCreateWindow( 400, //width 400, //height "window title",//title NULL, //monitor NULL //share ); //////////////////////////////////////////////////////////////////////////////// // ウィンドウを作成できなければ終了 if (window == nullptr) { glfwTerminate(); return 1; } glfwMakeContextCurrent(window);
double prev = glfwGetTime(); const double TIME = 0.1;
int angle = 0; while (glfwWindowShouldClose(window) == GL_FALSE) { int width, height; glfwGetFramebufferSize(window, &width, &height); ///////////////////// // 描画 glViewport(0, 0, width, height); glOrtho(-1, 1, -1, 1, -1, 1); glClearColor(0, 0, 0, 1); glClear(GL_COLOR_BUFFER_BIT); glLoadIdentity(); glPushMatrix();
// glfwGetTime()で現在時刻を秒で取得 double now = glfwGetTime(); // 現在時刻 - 前回更新時刻 が TIME秒より開いていたら // 定期的に行いたい処理を実行する if (now - prev > TIME) { prev = now; // 前回更新時刻更新 // ここで関数呼び出しなど必要な処理を行う // 今回はangleを増加するのみ。 printf("angle %d\n",angle); angle += 15; }
glRotatef(angle, 1, 0, 0); glBegin(GL_QUADS); glColor3d(1, 0, 0); glVertex2d(-0.7, -0.7); glColor3d(0, 1, 0); glVertex2d(-0.7, 0.7); glColor3d(0, 0, 1); glVertex2d(0.7, 0.7); glColor3d(1, 1, 1); glVertex2d(0.7, -0.7); glEnd(); glPopMatrix(); glFlush(); glfwSwapBuffers(window); // イベント取得 //glfwWaitEvents(); glfwPollEvents(); } glfwTerminate(); }
Ubuntu 22.04でFirefoxが起動できなかったので設定変更
firefoxを起動しようとしたら謎の長いエラーが出た。
user:~$ firefox
Gtk-Message: 20:10:15.794: Failed to load module "canberra-gtk-module"
Gtk-Message: 20:10:15.795: Failed to load module "canberra-gtk-module"
ATTENTION: default value of option mesa_glthread overridden by environment.
ATTENTION: default value of option mesa_glthread overridden by environment.
ATTENTION: default value of option mesa_glthread overridden by environment.
(firefox:14675): Gdk-WARNING **: 20:10:17.713: The program 'firefox' received an X Window System error.
This probably reflects a bug in the program.
The error was 'BadAlloc'.
(Details: serial 527 error_code 11 request_code 146 (unknown) minor_code 7)
(Note to programmers: normally, X errors are reported asynchronously;
that is, you will receive the error a while after causing it.
To debug your program, run it with the GDK_SYNCHRONIZE environment
variable to change this behavior. You can then get a meaningful
backtrace from your debugger if you break on the gdk_x_error() function.)
Exiting due to channel error.
対応
セーフモードで起動
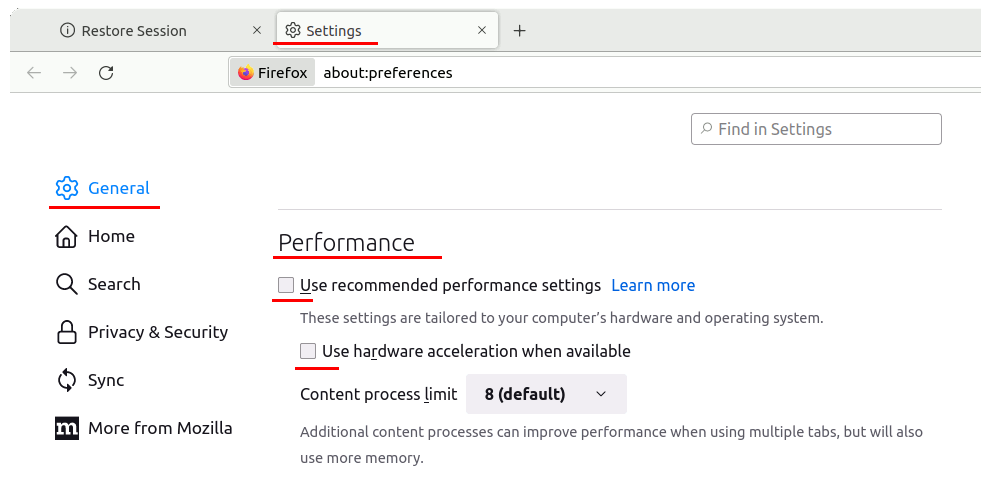
ハードウェアアクセラレーションの無効化
Performance → Use recommended performance setting → Use hardware acceleration when available
のチェックを外す。
CUDAのベクトル型を加減乗除する演算子
CUDAにはfloat3型などのベクトル型はあるが、ベクトル同士を計算する+,-などの演算子は定義されていない。
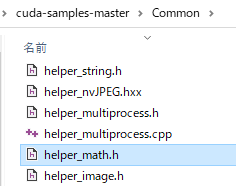
ではどうするかというと、CUDAのサンプルの中にhelper_math.hがあるので、これをダウンロードしてプロジェクトに追加する。
ダウンロード
https://github.com/NVIDIA/cuda-samples
導入
cuda-samples-master/Common/helper_math.h
使用例
#include "helper_math.h" // helper_math.h でincludeされているので不要 // #include "cuda_runtime.h" #include "device_launch_parameters.h" float3 my_calc(float3 a, float3 b) { return a + b; }
CUDAで複数の.cuファイルを使用する
CUDAのヘッダファイルの拡張子がcuhだと知り、では関数宣言を.cuhに書き、定義を.cuに書けば分割コンパイル的(?)なことができるのではないかと思ったのだが、リンクエラーが出たので対処法を調べた。
color_inverse関数(自作関数 , .cuhで宣言、.cuに定義)が見つからない
今回使ったのは以下。
・mytest.h ... CPU側から呼び出すときにincludeするヘッダファイル。
・mytest.cu ... CPU側から呼び出される処理。__global__関数も入っている。
・function.cu ... __device__関数のみが入っている。mytest.cuから呼び出される
・function.cuh ... function.cuの関数の宣言が入る。
CUDA側
設定
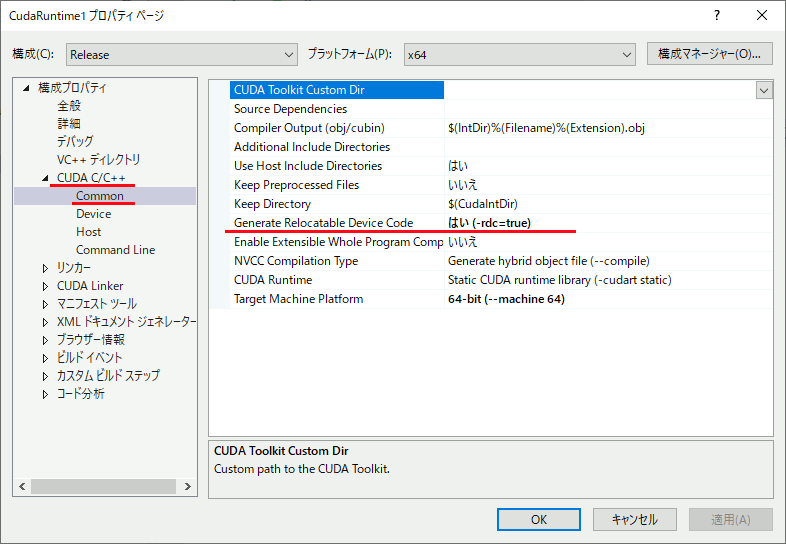
CUDA C/C++ → Common → Generate Relocatable Device Codeを はい (-rdc=true) に設定
mytest.h
#ifdef __DLL_EXPORT_DO #define DLL_PORT extern "C" _declspec(dllexport) #else #define DLL_PORT extern "C" _declspec(dllimport) #endif struct data_t { int width; int height; unsigned char* rgbdata; }; DLL_PORT void func_inverse(data_t* data);
mytest.cu
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> #include "mytest.h" // cudaのヘッダファイルは.cuhらしい #include "function.cuh" struct gpudata { int width; int height; unsigned char* c; }; __global__ void thread_inverse(gpudata data) { //このスレッドが担当する画素の位置を二次元座標で求める size_t xpos = blockIdx.x * blockDim.x + threadIdx.x; size_t ypos = blockIdx.y * blockDim.y + threadIdx.y; if (xpos < data.width && ypos < data.height) { size_t pos = (ypos * data.width + xpos) * 3; unsigned char* c = data.c + pos; // この関数はfunction.cuで定義されている color_inverse(c, xpos, ypos); } } void func_inverse(data_t* data) { // 16*16 == 256 < 512 int blockw = 16; int blockh = 16; dim3 block(blockw, blockh); int gridw = data->width / blockw + 1; int gridh = data->height / blockh + 1; dim3 grid(gridw,gridh); unsigned char* c_gpu; cudaMalloc((void**)&c_gpu, data->width*data->height*3);//GPU側にメモリを確保 cudaMemcpy( c_gpu, data->rgbdata, data->width* data->height*3, cudaMemcpyHostToDevice);//GPU側から実行結果を取得 gpudata gpud; gpud.width = data->width; gpud.height = data->height; gpud.c = c_gpu; thread_inverse<<<grid,block>>> (gpud);//GPU側の関数を呼出 cudaMemcpy( data->rgbdata, c_gpu, data->width * data->height * 3, cudaMemcpyDeviceToHost);//GPU側から実行結果を取得 cudaFree(c_gpu);//GPU側のメモリを解放 }
function.cuh
#include "cuda_runtime.h" __device__ void color_inverse(unsigned char* c, int width, int height);
function.cu
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include "function.cuh" __device__ void color_inverse(unsigned char* c, int width, int height) { c[0] = 255 - c[0]; c[1] = 255 - c[1]; c[2] = 255 - c[2]; }
C++側
#include <iostream> #pragma warning(disable:4996) #include "../CudaRuntime1/mytest.h" #pragma comment(lib,"CudaRuntime1.lib") void pnmP3_Write(const char* const fname, const int vmax, const int width, const int height, const unsigned char* const p);
int main() { data_t dat; dat.width = 100; dat.height = 50; unsigned char *c = new unsigned char[dat.width * dat.height * 3]; for (size_t i = 0; i < dat.width * dat.height; i++) { c[i * 3 + 0] = 0; c[i * 3 + 1] = 0; c[i * 3 + 2] = 255; } dat.rgbdata = c; func_inverse(&dat); pnmP3_Write("test.ppm", 255, dat.width, dat.height, dat.rgbdata); }
///////////////////////////////////////////// //画像ファイル書き出し///////////////////////// //! @brief PPM(RGB各1byte,カラー,テキスト)を書き込む //! @param [in] fname ファイル名 //! @param [in] vmax 全てのRGBの中の最大値 //! @param [in] width 画像の幅 //! @param [in] height 画像の高さ //! @param [in] p 画像のメモリへのアドレス //! @details RGBRGBRGB....のメモリを渡すと、RGBテキストでファイル名fnameで書き込む void pnmP3_Write(const char* const fname, const int vmax, const int width, const int height, const unsigned char* const p) { // PPM ASCII FILE* fp = fopen(fname, "wb"); fprintf(fp, "P3\n%d %d\n%d\n", width, height, vmax); size_t k = 0; for (size_t i = 0; i < (size_t)height; i++) { for (size_t j = 0; j < (size_t)width; j++) { fprintf(fp, "%d %d %d ", p[k * 3 + 0], p[k * 3 + 1], p[k * 3 + 2]); k++; } fprintf(fp, "\n"); } fclose(fp); }
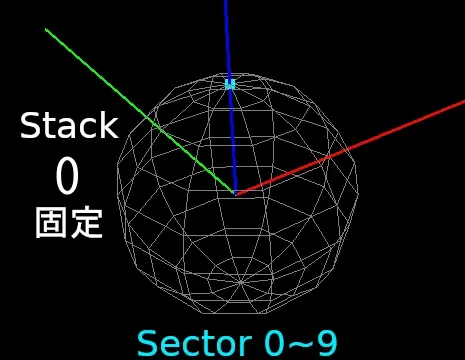
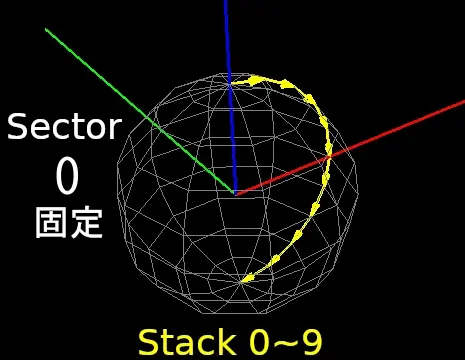
UV Sphereを描画(2)-頂点配列を作ってから表示
UV球の頂点配列を作成する。
UV球は物凄く簡単に言うとStack×Sectorのグリッドを丸めた物なので、二次元画像のようにWidth×Heightの配列として表現可能。
ただし例えば10の要素数の場合、0~10が必要になるのでループ回数は+1する事になる。
さらにこの作成方法では重複する頂点が出てくるので、それを嫌う場合はもう少し工夫が必要になる。

struct UVSphere { std::vector<glm::vec3> points; int stackCount; int SectorCount; };
// 球の頂点配列を作成 UVSphere create_uv_sphere(const int stackCount, const int SectorCount, const float r) { std::vector<glm::vec3> points; for (int stackStep = 0; stackStep < stackCount+1; stackStep++) { for (int sectorStep = 0; sectorStep < SectorCount+1; sectorStep++) { points.push_back(getPoint(sectorStep, SectorCount, stackStep, stackCount, r)); } } return UVSphere{ points, stackCount, SectorCount }; }
// 頂点配列から球を描画
void draw_uv_sphere(const UVSphere& uvq) { int Width = uvq.SectorCount+1; int Height = uvq.stackCount+1; for (int y = 0; y < Height - 1; y++) { for (int x = 0; x < Width - 1; x++) { int x2 = x + 1; int y2 = y + 1; int i1 = y * Width + x; int i2 = y2 * Width + x; int i3 = y2 * Width + x2; int i4 = y * Width + x2; glm::vec3 k1 = uvq.points[i1]; glm::vec3 k2 = uvq.points[i2]; glm::vec3 k3 = uvq.points[i3]; glm::vec3 k4 = uvq.points[i4]; // 四角形で描画 glBegin(GL_LINE_LOOP); glVertex3fv(glm::value_ptr(k1)); glVertex3fv(glm::value_ptr(k2)); glVertex3fv(glm::value_ptr(k3)); glVertex3fv(glm::value_ptr(k4)); glEnd(); } } }
UV Sphereを描画(1)
UV球は球を緯度、経度で表現したような球のことを言う。

参考文献に合わせてStep,Sectorで表現すると以下のような関係になる
glm::vec3 getPoint( const int sectorstep, const int sectorCount, const int stackstep, const int stackCount, const float r) { float theta = 2 * 3.14159 * (float(sectorstep) / sectorCount); float phi = 3.14159 / 2.f - 3.14159 * (float(stackstep) / stackCount); float x = (r * cos(phi)) * cos(theta); float y = (r * cos(phi)) * sin(theta); float z = r * sin(phi); return glm::vec3(x, y, z); }
// 球を描画 void draw_uv_sphere(const int stackCount, const int SectorCount,const float r) { for (int stackStep = 0; stackStep < stackCount; stackStep++) { for (int sectorStep = 0; sectorStep < SectorCount; sectorStep++) { glm::vec3 k1 = getPoint(sectorStep, SectorCount, stackStep, stackCount, r); glm::vec3 k2 = getPoint(sectorStep, SectorCount, stackStep + 1, stackCount, r); glm::vec3 k3 = getPoint(sectorStep + 1, SectorCount, stackStep + 1, stackCount, r); glm::vec3 k4 = getPoint(sectorStep + 1, SectorCount, stackStep, stackCount, r); // 四角形で描画 glBegin(GL_LINE_LOOP); glVertex3fv(glm::value_ptr(k1)); glVertex3fv(glm::value_ptr(k2)); glVertex3fv(glm::value_ptr(k3)); glVertex3fv(glm::value_ptr(k4)); glEnd(); /* k1 k1+1 (k4) +-------+ | /| | / | | / | | / | | / | | / | |/ | +-------+ k2 k2+1 (k3) */ } } }
参考文献
http://www.songho.ca/opengl/gl_sphere.html
bitnamiのdebianでキーボードを日本語配列に設定する
bitnamiをコンソールからいじりたいが英字配列キーボードになっている。これを日本語配列にする。
loadkeysを使えば一時的にレイアウトを変更できる。ただし最初は入っていないのでaptでインストール必要がある。
loadkeysインストール , 設定
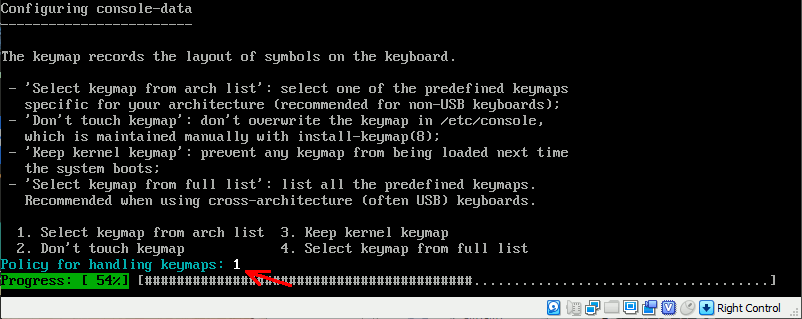
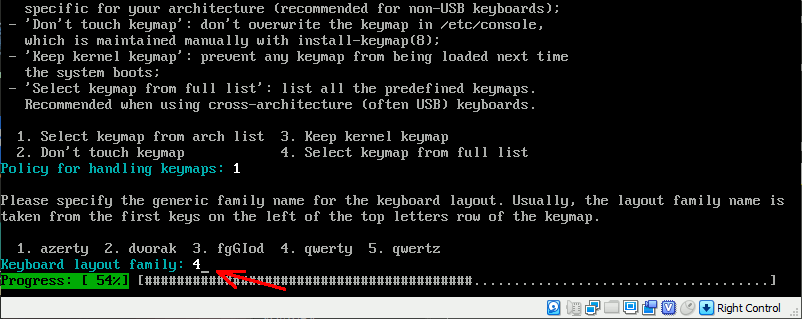
sudo apt install console-data
インストール中に設定を求められる。各項目の番号を入力していくとインストールが終わった段階で日本語キーボードになっている。
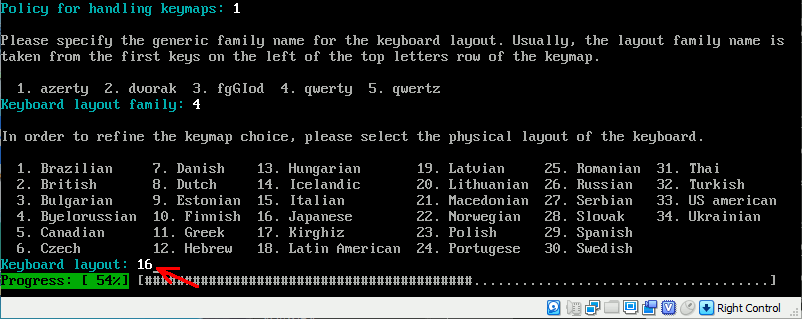
その後の設定
次回以降は以下のコマンドで日本語配列に変更する。
その他の方法
dpkg-reconfigureを使えば恒久的に変える事ができるらしい。ただしこちらの環境では次回起動時には戻っていた。