ICUライブラリのicu::UnicodeString::extractに指定するコードページにはどんなものがあるか
ICUライブラリを使って文字コードの変換を行うとき、例えば日本固有の文字コードに変換したいなら「Shift_JIS」や「EUC-JP」、中国固有の文字コードなら「GBK」「EUC-CN」など、変換先の文字コードを指定しなければならない。この文字コード名を「コードページ」というらしいが、Shift_JISやEUC-JPの他にどんな物があるか。
void test() { icu::UnicodeString us(u"いろはにほへと"); const char* code_page = "Shift_JIS"; // コードページ。他にどんな物があるか。 char dst_data[100]; int32_t len = us.extract(0, us.length(), dst_data, code_page); printf("%s (%d) \n",dst_data,len); }
コンバータ名一覧を取得する関数
マニュアルを読むと、どうやらConverter Namesという呼称でコードページを与えるらしい。そして使える名前一覧を取得する関数がいくつか用意されているらしい。
https://unicode-org.github.io/icu/userguide/conversion/converters.html#converter-names
ucnv_openAllNames
例えば、ucnv_openAllNames は
Get a list of all known converter names.
と、「全ての知られているコンバータ名を取得する」と書かれている。使い方はこんな感じ。
auto name_enum = ucnv_openAllNames(&err); int32_t len; const char* name; while (name = uenum_next(name_enum, &len, &err)) { printf("%s\n", name); } uenum_close(name_enum);
ucnv_openAllNamesでイテレータを取得して、uenum_nextでイテレータを前に進めるような使い方をする。
ただこれで得られる内容は膨大すぎてよくわからない。
ucnv_countAvailable
次に、ucnv_countAvailable は
Get a list of available converter names that can be opened.
と、「使えるコンバータのリストを取得する」と書かれている。使い方はこんな感じ。
int32_t convcount = ucnv_countAvailable(); for (int32_t i = 0; i < convcount; i++) { printf("[%03d] %s\n",i, ucnv_getAvailableName(i)); }
これでも200個以上出てくる上に、Shift_JISなどわかりやすい物がない。
ucnv_getAliases コードページの別名一覧を取得
そもそも同じコードページにも複数の表記法があるらしい。例えばShift_JIS,CP932,Windows-31J,MS932は(ほぼ)同じ意味になる。 ucnv_getAliases はそんな、あるコードページの仲間のコードページを探す。
int main() { UErrorCode err; const char* ALIAS = "Shift_JIS"; // 日本語のコードページ // ALIAS で表されるコードページの別名一覧を表示 uint16_t acount = ucnv_countAliases(ALIAS, &err); for (auto i = 0; i < acount; i++) { const char* code_page_arias = ucnv_getAlias(ALIAS, i, &err); printf("-- %s\n", code_page_arias); } getchar(); }
出力:
-- ibm-943
-- Shift_JIS
-- MS_Kanji
-- csShiftJIS
-- windows-31j
-- csWindows31J
-- x-sjis
-- x-ms-cp932
-- cp932
-- windows-932
-- cp943c
-- IBM-943C
-- ms932
-- pck
-- sjis
-- ibm-943_VSUB_VPUA
-- x-MS932_0213
-- x-JISAutoDetect
CP932 vs Shift_JIS
Shift_JIS を ucnv_getAliases にかけるとエイリアスが大量に出てくるのだが違いがあるのかよくわからない。拡張文字の有無など微細な違いがあるらしいCP932とShift_JISにそれぞれ変換してみた。
#include <fstream> #include <iostream> #include <unicode/ucnv.h> #include <unicode/unistr.h> #pragma comment(lib, "icuuc.lib") // 以下のdllを要求される // icudt69.dll // icuuc69.dll
void Converter(const icu::UnicodeString& us,const char* dstCode) { //内部形式の文字コードを目的の文字コードへ変換 char dst_data[100]; int32_t len = us.extract(0, us.length(), dst_data, dstCode); printf("length: %d\n", len); std::string textname = "C:\\dev\\icu-test\\converted-"; textname += dstCode; textname += ".txt"; ///////////////////////////////
// 文字コード変換した内容をファイル出力 std::fstream w( textname, std::ios::out | std::ios::binary | std::ios::trunc); w << dst_data; }
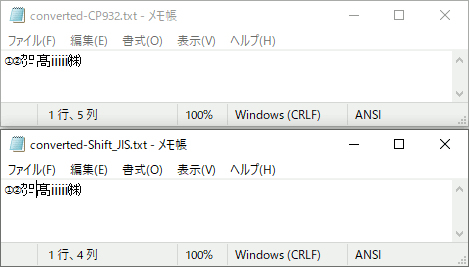
int main() { UErrorCode err; const char* ALIAS = "Shift_JIS"; // 日本語のコードページ //std::u16string src_data = u"いろはにほへと"; // 日本語 // NEC拡張文字 // ①②㌍ // IBM拡張文字 // 髙ⅱⅲ㈱ std::u16string jps = u"①②㌍髙ⅱⅲ㈱"; // ICUの内部表現へ変更 icu::UnicodeString ustr(jps.c_str()); Converter(ustr, "Shift_JIS");// コードページを指定して変換 Converter(ustr, "CP932"); getchar(); }
実行結果。特に変換できない文字は出てこなかった。
指定できそうなコードページを調べる
ICUライブラリのページではないようだがIBMのページなので、ここの一覧から選ぶことができそうである。いくつか拾い上げて ucnv_getAliases に与えると表のとおりの結果が返ってきている。
おまけ
中国語やギリシャ語への変換例。確認方法が面倒。Converterは前述のものを使用。
ギリシャ語はWordでフォントをTimes New Romanにすると確認できる。
int main() { UErrorCode err; const char* ALIAS = "EUC-CN"; // 中国語のコードページ std::u16string src_data = u"什么"; // 中国語 icu::UnicodeString ustr(src_data.c_str()); Converter(ustr, ALIAS); getchar(); }
int main() { UErrorCode err; const char* ALIAS = "ibm737"; // ギリシャ語のコードページ std::u16string src_data = u"πανσέληνος"; // ギリシャ語 icu::UnicodeString ustr(src_data.c_str()); Converter(ustr, ALIAS); getchar(); }
参考:
本当は怖くないCP932
https://qiita.com/kasei-san/items/cfb993786153231e5413