月火水木金土日
CUDAのblock,gridの計算をファイル出力してみる
久しぶりにCUDAを勉強しようと思ったら忘れていたので、block,gridの設定がカーネル内でどうなるかを確認するプログラムを書いた。
#include "cuda_runtime.h"
#include "device_launch_parameters.h" #include <stdio.h> #include <stdlib.h>
/////////////////////////////////////////////// // GPU側 ////////////////////////////////////// __global__ void threadpos( unsigned char* c, const int width, const int height) { //アクセス法 //このスレッドが担当する画素の位置を二次元座標で求める size_t xpos = blockIdx.x * blockDim.x + threadIdx.x; size_t ypos = blockIdx.y * blockDim.y + threadIdx.y; if (xpos >= width || ypos >= height)return; int pos = ypos * width + xpos; c[pos * 6 + 0] = blockIdx.x; c[pos * 6 + 1] = blockIdx.y; c[pos * 6 + 2] = threadIdx.x; c[pos * 6 + 3] = threadIdx.y; c[pos * 6 + 4] = xpos; c[pos * 6 + 5] = ypos; } /////
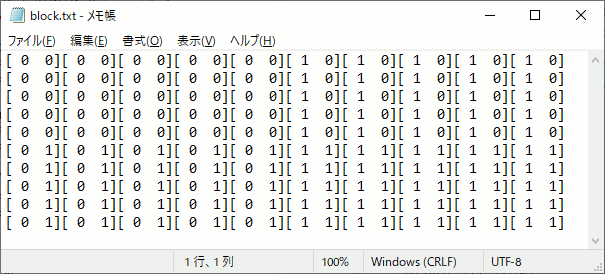
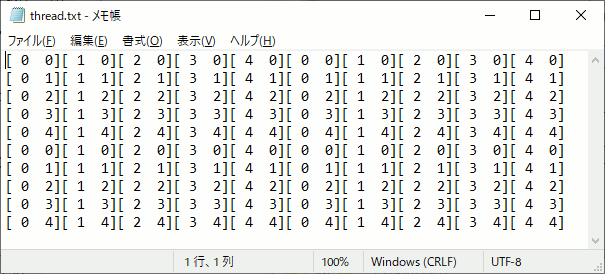
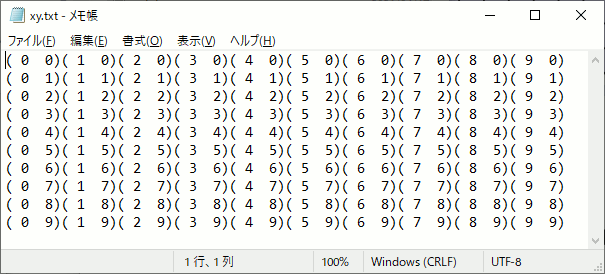
int main() { int width = 10; int height = 10; int item = 6; // 最小単位 合計で512未満 //5×5の領域に分けて計算する dim3 block(5, 5); //グリッド数 dim3 grid(2, 2); unsigned char* p_cpu = new unsigned char[width*height*item]; for (int i = 0; i < width*height*item; i++) { p_cpu[i] = 0; } unsigned char* p_gpu;//GPU側メモリ確保 cudaMalloc((void**)&p_gpu, width*height * item); threadpos << <grid, block >> > (p_gpu, width,height); //GPU→CPU側へメモリコピー cudaMemcpy(p_cpu, p_gpu, width*height * item, cudaMemcpyDeviceToHost); cudaFree(p_gpu); /////////////////////////////////////////////// // 結果出力 FILE* fpblock = fopen("block.txt", "w"); FILE* fpthread = fopen("thread.txt", "w"); FILE* fpxy = fopen("xy.txt", "w"); for (size_t y = 0; y < height; y++) { for (size_t x = 0; x < width; x++) { int pos = y * width + x; fprintf(fpblock,"[%2d %2d]", p_cpu[pos * item + 0], p_cpu[pos * item + 1] ); fprintf(fpthread, "[%2d %2d]", p_cpu[pos * item + 2], p_cpu[pos * item + 3] ); fprintf(fpxy, "(%2d %2d)", p_cpu[pos * item + 4], p_cpu[pos * item + 5] ); } fprintf(fpblock,"\n"); fprintf(fpthread, "\n"); fprintf(fpxy, "\n"); } fclose(fpblock); fclose(fpthread); fclose(fpxy); delete[] p_cpu; return 0; }