GLSLを試す (3) テクスチャ
変数の定義
typedef GLubyte rgb_t[3]; //テクスチャ用 typedef GLfloat points_t[3]; //モデルの座標用 typedef GLfloat texcoord_t[2];//テクスチャ座標用 const int P_COUNT = 4; //頂点データ GLuint vertexbuffer; points_t position[P_COUNT]; //テクスチャ座標データ texcoord_t texcoord[P_COUNT]; GLuint texcoordbuffer; //テクスチャデータ rgb_t texdata[P_COUNT]; GLuint textureID;
データとバッファの準備
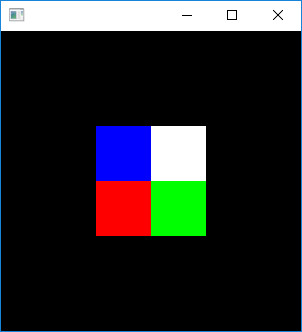
void prepare_buffers() { //テクスチャ(画像)作成 // 2*2の画像 texdata[0][0] = 255; texdata[0][1] = 0; texdata[0][2] = 0; texdata[1][0] = 0; texdata[1][1] = 255; texdata[1][2] = 0; texdata[2][0] = 0; texdata[2][1] = 0; texdata[2][2] = 255; texdata[3][0] = 255; texdata[3][1] = 255; texdata[3][2] = 255; ////////////////////////////////////////// ////////////////////////////////////////// //頂点座標の定義 (四角形) // いつもなら glVertex3fv等て指定するもの position[0][0] = -0.7; position[0][1] = 0.7; position[0][2] = 0; position[1][0] = -0.7; position[1][1] = -0.7; position[1][2] = 0; position[2][0] = 0.7; position[2][1] = -0.7; position[2][2] = 0; position[3][0] = +0.7; position[3][1] = +0.7; position[3][2] = 0; ////////////////////////////////////////// ////////////////////////////////////////// //テクスチャ座標の定義 //いつもならglTexCoord2f等で指定するもの texcoord[0][0] = 0; texcoord[0][1] = 1; texcoord[1][0] = 0; texcoord[1][1] = 0; texcoord[2][0] = 1; texcoord[2][1] = 0; texcoord[3][0] = 1; texcoord[3][1] = 1; ////////////////////////////////////////// ////////////////////////////////////////// //テクスチャの作成 // 普通のテクスチャ作成 glGenTextures(1, &textureID); glBindTexture(GL_TEXTURE_2D, textureID); int TEXWIDTH = 2; // 2*2の画素数 int TEXHEIGHT = 2; glPixelStorei(GL_UNPACK_ALIGNMENT, 1); // テクスチャの割り当て glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, TEXWIDTH, TEXHEIGHT, 0, GL_RGB, GL_UNSIGNED_BYTE, texdata); // テクスチャを拡大・縮小する方法の指定 glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); ////////////////////////////////////////// ////////////////////////////////////////// //頂点バッファの作成 glGenBuffers(1, &vertexbuffer); glBindBuffer(GL_ARRAY_BUFFER, vertexbuffer); glBufferData(GL_ARRAY_BUFFER, 3 * P_COUNT * sizeof(GLfloat), position, GL_STATIC_DRAW); //テクスチャ座標バッファの作成 glGenBuffers(1, &texcoordbuffer); glBindBuffer(GL_ARRAY_BUFFER, texcoordbuffer); glBufferData(GL_ARRAY_BUFFER, 2 * P_COUNT * sizeof(GLfloat), texcoord, GL_STATIC_DRAW); }
描画関数
void display(void) { glClearColor(0, 0, 0, 1); glClear(GL_COLOR_BUFFER_BIT); glDisable(GL_CULL_FACE);//カリングを無効にする /////////////////////////////////// // 行列の設定 glMatrixMode(GL_PROJECTION); glLoadIdentity(); gluPerspective(65, 1, 0.1, 10); glMatrixMode(GL_MODELVIEW); glLoadIdentity(); glTranslated(0.0, 0.0, -3); /////////////////////////////////// // シェーダを使う glUseProgram(ProgramID); /////////////////////////////////// // 頂点バッファを有効化 glEnableVertexAttribArray(0); glBindBuffer(GL_ARRAY_BUFFER, vertexbuffer); glVertexAttribPointer( 0, // 属性0 3, // 1要素の個数。GLfloatのx,y,zなので3 GL_FLOAT, // タイプ GL_FALSE, // 正規化しない(データが整数型の時) 0, // ストライド (void*)0 // 配列バッファオフセット ); /////////////////////////////////// //テクスチャ座標バッファの有効化 glEnableVertexAttribArray(1); glBindBuffer(GL_ARRAY_BUFFER, texcoordbuffer); glVertexAttribPointer( 1, // 属性1 2, // 1要素の個数。GLfloatのu,vなので2 GL_FLOAT, // タイプ GL_FALSE, // 正規化しない(データが整数型の時) 0, // ストライド (void*)0 // 配列バッファオフセット ); /////////////////////////////////// // 四角形の描画 glDrawArrays(GL_TRIANGLE_FAN, 0, P_COUNT); glDisableVertexAttribArray(0); glDisableVertexAttribArray(1); glFlush(); }
頂点シェーダ
#version 460 core layout (location = 0) in vec3 aPos;//ポリゴンの頂点座標 layout (location = 1) in vec2 texcd;//座標に対応するテクスチャ座標 out vec2 vTexCoord;//テクスチャ座標の出力先 uniform mat4 gl_ModelViewMatrix; uniform mat4 gl_ProjectionMatrix; void main() { gl_Position = gl_ProjectionMatrix * gl_ModelViewMatrix * vec4(aPos, 1.0); vTexCoord = texcd;//フラグメントシェーダへテクスチャ座標を渡す }
フラグメントシェーダ
#version 460 core out vec4 FragColor;//色の出力先 uniform sampler2D uTex;//テクスチャデータ(自動でセットされている) in vec2 vTexCoord;//頂点シェーダから渡されたテクスチャ座標 void main() {
//テクスチャデータとテクスチャ座標から色を決定 FragColor = texture(uTex,vTexCoord); }
GLSLを試す (2) 変換行列の受け渡し
頂点シェーダへの変換行列の受け渡しの方法は二つ。
built-in変数を使う場合
C言語側
void display(void) { glClearColor(0, 0, 0, 1); glClear(GL_COLOR_BUFFER_BIT); glMatrixMode(GL_PROJECTION); glLoadIdentity(); gluPerspective(65, 1, 0.1, 10); glMatrixMode(GL_MODELVIEW); glLoadIdentity(); glTranslated(0.0, 0.0, -0.8); // シェーダを使う glUseProgram(ProgramID); // 最初の属性バッファ:頂点 glEnableVertexAttribArray(0); glBindBuffer(GL_ARRAY_BUFFER, vertexbuffer); glVertexAttribPointer( 0, // シェーダ内のlayoutとあわせる 3, // サイズ GL_FLOAT, // タイプ GL_FALSE, // 正規化しない(データが整数型の時) 0, // ストライド (void*)0 // 配列バッファオフセット ); // カラーバッファを有効にする glEnableVertexAttribArray(1); glBindBuffer(GL_ARRAY_BUFFER, colorbuffer); glVertexAttribPointer( 1, // シェーダ内のlayoutとあわせる 3, // サイズ GL_FLOAT, // タイプ GL_FALSE, // 正規化しない(データが整数型の時) 0, // ストライド (void*)0 // 配列バッファオフセット ); // 三角形を描きます! glDrawArrays(GL_TRIANGLES, 0, 3); // 頂点0から始まります。合計3つの頂点です。→1つの三角形です。 glDisableVertexAttribArray(0); glDisableVertexAttribArray(1); glFlush(); }
頂点シェーダ側
uniform変数 gl_ModelViewMatrixやgl_ProjectionMatrixでOpenGLの行列にアクセス出来る。これらはglUniformMatrix4fvで設定する必要が無い。
#version 460 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 incolor; out vec4 vertexColor; uniform mat4 gl_ModelViewMatrix; uniform mat4 gl_ProjectionMatrix; void main() { gl_Position = gl_ProjectionMatrix * gl_ModelViewMatrix * vec4(aPos, 1.0); vertexColor = vec4(incolor, 1.0); }
この他のBuilt-In-Matrixは以下を参照
https://en.wikibooks.org/wiki/GLSL_Programming/Applying_Matrix_Transformations
glUniformMatrix4fvで共有する場合
C言語側
自分のプログラム内で行列を用意してglUniformMatrix4fvでGPUへ転送する。Projection Matrixを計算するコードを自前で書くのも間抜けなので
https://www.khronos.org/opengl/wiki/GluPerspective_code
などをコピペすると良い。
void display(void) { glClearColor(0, 0, 0, 1); glClear(GL_COLOR_BUFFER_BIT); // シェーダを使う glUseProgram(ProgramID); //変換行列を定義 // uniform mat4がfloatのため、こちらもfloatでないといけない GLfloat mfproj[16]; GLfloat mftran[16]; mfproj[ 0] = 2.26961231; mfproj[ 1] = 0.0; mfproj[ 2] = 0.0; mfproj[ 3] = 0.0; mfproj[ 4] = 0.0; mfproj[ 5] = 2.41421366; mfproj[ 6] = 0.0; mfproj[ 7] = 0.0; mfproj[ 8] = 0.0; mfproj[ 9] = 0.0; mfproj[10] = -1.00020003; mfproj[11] = -1.00000000; mfproj[12] = 0.0; mfproj[13] = 0.0; mfproj[14] = -0.0200020000; mfproj[15] = 0.0; mftran[ 0] = 1.0; mftran[ 1] = 0.0; mftran[ 2] = 0.0; mftran[ 3] = 0.0; mftran[ 4] = 0.0; mftran[ 5] = 1.0; mftran[ 6] = 0.0; mftran[ 7] = 0.0; mftran[ 8] = 0.0; mftran[ 9] = 0.0; mftran[10] = 1.0; mftran[11] = 0.0; mftran[12] = 0.2; mftran[13] = 0.0; mftran[14] = 0.0; mftran[15] = 1.0; GLint proj = glGetUniformLocation(ProgramID, "m_projection"); GLint tran = glGetUniformLocation(ProgramID, "m_transform"); glUniformMatrix4fv(proj, 1, GL_FALSE, mfproj); glUniformMatrix4fv(tran, 1, GL_FALSE, mftran); // 最初の属性バッファ:頂点 glEnableVertexAttribArray(0); glBindBuffer(GL_ARRAY_BUFFER, vertexbuffer); glVertexAttribPointer( 0, // 属性0 3, // サイズ GL_FLOAT, // タイプ GL_FALSE, // 正規化しない(データが整数型の時) 0, // ストライド (void*)0 // 配列バッファオフセット ); // 2nd attribute buffer : colors glEnableVertexAttribArray(1); glBindBuffer(GL_ARRAY_BUFFER, colorbuffer); glVertexAttribPointer( 1, // 属性1 3, // サイズ GL_FLOAT, // タイプ GL_FALSE, // 正規化しない(データが整数型の時) 0, // ストライド (void*)0 // 配列バッファオフセット ); // 三角形を描きます! glDrawArrays(GL_TRIANGLES, 0, 3); glDisableVertexAttribArray(0); glDisableVertexAttribArray(1); glFlush(); }
頂点シェーダ側
#version 460 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 incolor; out vec4 vertexColor; uniform mat4 m_transform; uniform mat4 m_projection; void main() { gl_Position = m_projection * m_transform * vec4(aPos, 1.0); vertexColor = vec4(incolor, 1.0); }
GLSLを試す (1)
glBegin - glEndが大好きなのだけれどそろそろモダンOpenGLにも触っておかないとまずいということでVBOと頂点シェーダとフラグメントシェーダの基礎を触っておく。
ややこしいのは、VBO(=頂点バッファ)のコードと頂点シェーダ関連コードが、直接的な関連性が低いのに密接に絡み合っているところ。
CPU側ソースコード
glut初期化コード
glutを使わないのなら勿論必要ない。ただしglewを使うのでその初期化が必要。
余談だけれどもgl.hを使うのならinclude順はglew.h→gl.hとなる。さらにwindowsではgl.hの前にwindows.hを入れなければならない。つまりwgl等でウィンドウを作成する場合、
#include <windows.h>
#include <gl/glew.h>
#include <gl/GL.h>
のような順番になる。この例ではglutだけなのでgl.hは自分でincludeしない。ただしglut.hの中でgl.hがincludeされているので、順番はglew.h→glut.hでなければならない。さもなくば
fatal error C1189: #error: gl.h included before glew.h
と言われる。
#pragma warning(disable:4996) #pragma comment(lib,"glew32.lib") #include <gl/glew.h> #include <GL/glut.h> #include <fstream> #include <sstream> #include <vector> #include <algorithm> void init(void); void display(void); int main(int argc, char *argv[]) { glutInit(&argc, argv); glutInitDisplayMode(GLUT_RGBA); glutCreateWindow(argv[0]); glutDisplayFunc(display);
glewInit(); // glewの初期化 init(); glutMainLoop(); return 0; }
初期化コード呼び出し元
void init(void) { //頂点データと色情報の作成 prepare_buffers(); //頂点シェーダの準備 prepare_vertex_shader(); //フラグメントシェーダの準備 prepare_fragment_shader(); //プログラムのリンク link_program(); }
頂点データとバッファの作成コード
今までglBegin~glEndで囲んでいたデータを配列として作成して先にGPUへ転送しておく。
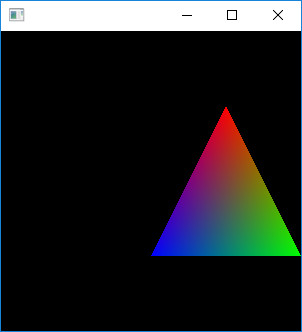
//バッファとデータ typedef GLfloat points_t[3]; GLuint vertexbuffer;//バッファのIDを格納する変数 GLuint colorbuffer;//バッファのIDを格納する変数 points_t position[3]; points_t color[3]; ////////////////////////////////////////////////// void prepare_buffers() { //頂点座標 position[0][0] = 0; position[0][1] = 0.5; position[0][2] = 0; position[1][0] = 0.5; position[1][1] = -0.5; position[1][2] = 0; position[2][0] = -0.5; position[2][1] = -0.5; position[2][2] = 0; //色 color[0][0] = 1.0; color[0][1] = 0.0; color[0][2] = 0.0; color[1][0] = 0.0; color[1][1] = 1.0; color[1][2] = 0.0; color[2][0] = 0.0; color[2][1] = 0.0; color[2][2] = 1.0; glGenBuffers(1, &vertexbuffer); glBindBuffer(GL_ARRAY_BUFFER, vertexbuffer); glBufferData(
GL_ARRAY_BUFFER,
3 * 3 * sizeof(GLfloat),
position,
GL_STATIC_DRAW); glGenBuffers(1, &colorbuffer); glBindBuffer(GL_ARRAY_BUFFER, colorbuffer); glBufferData(
GL_ARRAY_BUFFER,
3 * 3 * sizeof(GLfloat),
color,
GL_STATIC_DRAW); }
頂点シェーダの準備
クソ長く見えるがやっていることは
①glCreateShaderでシェーダのIDを作成
②glShaderSourceでシェーダのソースコードをシェーダに教える
③glCompileShaderでシェーダをコンパイル
④glGetShaderivでシェーダのコンパイルに成功したかを確認
⑤glGetShaderInfoLogでエラー内容を確認
だけで本質的には十行程度。ファイル読み込み部がコードの長さを異常に長くみせている。本質とは直接関係ないのに。
GLuint VertexShaderID;
void prepare_vertex_shader() { ////////////////////////////////////////////// // シェーダを作ります // (作るといっても宣言みたいなもの) VertexShaderID = glCreateShader(GL_VERTEX_SHADER); //////////////////////////////////////////// // ファイルから頂点シェーダを読み込みます。
// 注意 ここはSTLのifstreamとかstringstreamの使い方の話で、
// OpenGL命令は一つも無い。 const char * vertex_file_path = "C:\\test\\verts.sh"; std::string VertexShaderCode; std::ifstream VertexShaderStream(vertex_file_path, std::ios::in); if (VertexShaderStream.is_open()) { std::stringstream sstr; sstr << VertexShaderStream.rdbuf(); VertexShaderCode = sstr.str(); VertexShaderStream.close(); } //////////////////////////////////////////// // 頂点シェーダをコンパイルします。 printf("Compiling shader : %s\n", vertex_file_path); char const * VertexSourcePointer = VertexShaderCode.c_str(); glShaderSource(VertexShaderID, 1, &VertexSourcePointer, NULL); glCompileShader(VertexShaderID); //////////////////////////////////////////// // エラーチェック GLint Result = GL_FALSE; int InfoLogLength; // 頂点シェーダをチェックします。 glGetShaderiv(VertexShaderID, GL_COMPILE_STATUS, &Result); glGetShaderiv(VertexShaderID, GL_INFO_LOG_LENGTH, &InfoLogLength); if (Result == FALSE) { std::vector<char> VertexShaderErrorMessage(InfoLogLength); glGetShaderInfoLog(VertexShaderID, InfoLogLength, NULL, &VertexShaderErrorMessage[0]); fprintf(stdout, "%s\n", &VertexShaderErrorMessage[0]); } }
あとエラー処理が行数を嵩張らせている。普通(?)OpenGLで描画とかするときに、エラーを無視してもなんとなく上手く動いているように見えることも多いけれど、シェーダのコンパイルをする以上、コンパイルエラーをちゃんと見ないとデバッグ出来ないのでエラー処理はちゃんと入れないとまずい。
これはエラーを見る癖をつけましょうとかの精神論ではなく、見ないと何故動かないのかが全くわからないから省きようがない。
フラグメントシェーダの準備
頂点シェーダとの違いは、読み込むファイルと、glCreateShaderに渡す定数がGL_FRAGMENT_SHADERになっているところぐらいで、ほぼ同じ。
GLuint FragmentShaderID;
void prepare_fragment_shader() { ///////////////////////////////////////////// // シェーダを作ります。 FragmentShaderID = glCreateShader(GL_FRAGMENT_SHADER); ///////////////////////////////////////////// // ファイルからフラグメントシェーダを読み込みます。 const char * fragment_file_path = "C:\\test\\frags.sh"; std::string FragmentShaderCode; std::ifstream FragmentShaderStream(fragment_file_path, std::ios::in); if (FragmentShaderStream.is_open()) { std::stringstream sstr; sstr << FragmentShaderStream.rdbuf(); FragmentShaderCode = sstr.str(); FragmentShaderStream.close(); } ///////////////////////////////////////////// // フラグメントシェーダをコンパイルします。 printf("Compiling shader : %s\n", fragment_file_path); char const * FragmentSourcePointer = FragmentShaderCode.c_str(); glShaderSource(FragmentShaderID, 1, &FragmentSourcePointer, NULL); glCompileShader(FragmentShaderID); GLint Result = GL_FALSE; int InfoLogLength; /////////////////////////////////////////////
// フラグメントシェーダをチェックします。 glGetShaderiv(FragmentShaderID, GL_COMPILE_STATUS, &Result); glGetShaderiv(FragmentShaderID, GL_INFO_LOG_LENGTH, &InfoLogLength); if (Result == GL_FALSE) { std::vector<char> FragmentShaderErrorMessage(InfoLogLength); glGetShaderInfoLog(FragmentShaderID, InfoLogLength, NULL, &FragmentShaderErrorMessage[0]); fprintf(stdout, "%s\n", &FragmentShaderErrorMessage[0]); } }
プログラムのリンク
頂点シェーダとフラグメントシェーダのセットをProgramとして一つに束ねる。
ここもやっていることは、
①glCreateProgram でプログラムIDを取得
②glAttachShader でシェーダを登録
③glLinkProgram プログラムをリンク
④glGetProgramiv でプログラムのエラーをチェック
⑤glGetProgramInfoLog でプログラムのエラーの内容をチェックする
GLuint ProgramID;
void link_program() { GLint Result = GL_FALSE; int InfoLogLength; //////////////////////////////////////// // プログラムをリンクします。 fprintf(stdout, "Linking program\n"); ProgramID = glCreateProgram(); glAttachShader(ProgramID, VertexShaderID); glAttachShader(ProgramID, FragmentShaderID); glLinkProgram(ProgramID); //////////////////////////////////////// // プログラムをチェックします。 glGetProgramiv(ProgramID, GL_LINK_STATUS, &Result); glGetProgramiv(ProgramID, GL_INFO_LOG_LENGTH, &InfoLogLength); std::vector<char> ProgramErrorMessage((std::max)(InfoLogLength, int(1))); glGetProgramInfoLog(ProgramID, InfoLogLength, NULL, &ProgramErrorMessage[0]); fprintf(stdout, "%s\n", &ProgramErrorMessage[0]); }
シェーダ側ソースコード
頂点シェーダ (verts.sh)
拡張子は何でもいい。shだとシェルスクリプトと勘違いしそうなら.verts、.fragsなどでいい。
#version 460 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 incolor; out vec4 vertexColor; uniform mat4 gl_ModelViewMatrix; uniform mat4 gl_ProjectionMatrix; void main() { gl_Position = gl_ProjectionMatrix * gl_ModelViewMatrix * vec4(aPos, 1.0); vertexColor = vec4(incolor, 1.0); }
フラグメントシェーダ(frags.sh)
#version 460 core out vec4 FragColor; in vec4 vertexColor; void main() { FragColor = vertexColor; }
CPU側 描画
void display(void) { glClearColor(0, 0, 0, 1); glClear(GL_COLOR_BUFFER_BIT); glLoadIdentity(); glTranslated(0.5, 0.0, 0.0);//平行移動 // シェーダを使う glUseProgram(ProgramID); // 頂点バッファ:頂点 glEnableVertexAttribArray(0); glBindBuffer(GL_ARRAY_BUFFER, vertexbuffer); glVertexAttribPointer( 0, // シェーダ内のlayoutとあわせる 3, // 1要素の要素数(x,y,z)で3要素 GL_FLOAT, // タイプ GL_FALSE, // 正規化しない(データが整数型の時) 0, // ストライド (void*)0 // 配列バッファオフセット ); // カラーバッファを有効にする glEnableVertexAttribArray(1); glBindBuffer(GL_ARRAY_BUFFER, colorbuffer); glVertexAttribPointer( 1, // シェーダ内のlayoutとあわせる 3, // 1要素の要素数(r,g,b)で3要素 GL_FLOAT, // タイプ GL_FALSE, // 正規化しない(データが整数型の時) 0, // ストライド (void*)0 // 配列バッファオフセット ); // 三角形を描きます! glDrawArrays(GL_TRIANGLES, 0, 3); glDisableVertexAttribArray(0);//バッファを無効にする glDisableVertexAttribArray(1); glFlush(); }
その他
後半へ続く・・・
C++でsplit (3) – utf16版
1.補助関数の作成
次のutf16文字へのポインタを取得する
char16_t* next_c_u16(const char16_t* c) { if (IS_SURROGATE_PAIR(c[0], c[1]) == true) return (char16_t*)c + 2; return (char16_t*)c + 1; }
utf16文字を一文字取り出す
//utf16文字を一文字取り出す void ext_c_u16(char16_t* const dst, const char16_t* src,int* size) { int sz; if (IS_SURROGATE_PAIR(src[0], src[1]) == true) sz = 4; else sz = 2; memcpy(dst, src, sz); dst[sz/2] = char16_t(0); if(size) *size = sz; }
utf16文字を比較する
//utf16文字を比較する bool cmp_c_u16(const char16_t* c1, const char16_t* c2) { int K = bytes_c_u16(c1); int L = bytes_c_u16(c2); if (K != L) return false; bool issame = (memcmp(c1, c2, K) == 0); return issame; }
utf16文字のバイト数を返す関数
//文字のバイト数を取得 int bytes_c_u16(const char16_t* c) { if (IS_SURROGATE_PAIR(c[0], c[1]) == true) return 4; return 2; }
split関数本体
std::vector<std::u16string> split_u16(const char16_t* src, const char16_t* del) { char16_t tmp[10]; std::vector<std::u16string> result; std::u16string tmps; while (*src) { //デリミタを飛ばす const char16_t* p = src; while (cmp_c_u16(src, del) == true && *src != '\0') src = next_c_u16(src); //デリミタに遭遇するまで文字を追加し続ける while (cmp_c_u16(src, del) != true && *src != '\0') { ext_c_u16(tmp, src, nullptr);//一文字取り出す tmps += tmp; src = next_c_u16(src); } if (tmps.size()) { result.push_back(tmps); } tmps.clear(); } return result; }
実験1
int main() { setlocale(LC_ALL, ""); char16_t* u16 = (char16_t*)L"C:\\いろは\\山田\\abc\\"; std::ofstream f(L"c:\\test\\test.txt", std::ios::out | std::ios::binary); std::vector<std::u16string> ret = split_u16(u16, (char16_t*)L"\\"); for (size_t i = 0; i < ret.size(); i++) { wprintf(L"[%s]", (wchar_t*)ret[i].c_str()); } f.close(); return 0; }
結果1
[C:][いろは][山田][abc]
実験2

結果2

余談
サロゲートペアの文字一覧はここから
WordPressで上記文字を入力したところなぜか記事の保存ができなかったので、実験2は画像にしている。
C++でsplit (2) – マルチバイト版,’\’対応
1.補助関数作成
次のマルチバイト文字へのポインタを取得する関数
//次のマルチバイト文字へのポインタを取得 const char* next_c_mb(const char* c) { int L = mblen(c, 10); return c + L; }
マルチバイト文字を一文字取り出す
//マルチバイト文字を一文字取り出す void ngetc(char* const dst,const char* src) { int L = mblen(src, 10); memcpy(dst, src, L); dst[L] = '\0'; }
マルチバイト文字を比較する
//マルチバイト文字を比較する bool nchr_cmp(const char* c1, const char* c2) { int K = mblen(c1, 10); int L = mblen(c2, 10); if (K != L) return false; bool issame = (strncmp(c1, c2, K) == 0); return issame; }
2.split関数本体
std::vector<std::string> split_mb(const char* src, const char* del) { char tmp[10]; std::vector<std::string> result; std::string tmps; while (*src) { //デリミタを飛ばす const char* p = src; while (nchr_cmp(src, del) == true && *src != '\0') src= next_c_mb(src); //デリミタに遭遇するまで文字を追加し続ける while (nchr_cmp(src, del) != true && *src != '\0') { ngetc(tmp, src);//一文字取り出す tmps += tmp; src = next_c_mb(src); } if (tmps.size()) { result.push_back(tmps); } tmps.clear(); } return result; }
実験
setlocale(LC_ALL, ""); std::vector<std::string> ret = split_mb("C:\\日本語表示フォルダ\\test\\contains", "\\"); for (size_t i = 0; i < ret.size(); i++) { printf("[%s]", ret[i].c_str()); }
結果
[C:][日本語表示フォルダ][test][contains]
注意
mblenはlocaleの影響を受けるのでsetlocaleする。
しない場合、’表’が1byteとしてカウントされてしまう。
C++でsplit (1) – strtok版
strtokによる分割プログラム
strtokを使った典型的なsplitの結果をstringのvectorに格納する。
ありきたりだがとりあえず此が一番事故がない。
#include <string.h> #include <vector> //! @brief 文字列分割関数(マルチバイト文字版) //! @param [in] src 対象の文字列 //! @param [in] del 区切り文字を列挙した文字列 //! @return 分割後の文字列 std::vector<std::string> split_mb(const char* src, const char* del) { std::vector<std::string> result; //strtokは元の文字列を書き換えるので //作業用の領域を作って元データをコピーする std::vector<char> vtxt(strlen(src) + 1,'\0'); char *txt = &vtxt[0]; strcpy(txt, src); char* t = strtok(txt, del); if (strlen(t) != 0) { result.push_back(t); } while (t != NULL) { t = strtok(NULL, del); if (t != NULL) { result.push_back(t); } } return result; } //! @brief 文字列分割関数(ワイド文字版) //! @param [in] src 対象の文字列 //! @param [in] del 区切り文字を列挙した文字列 //! @return 分割後の文字列 std::vector<std::wstring> split_wc(const wchar_t* src, const wchar_t* del) { std::vector<std::wstring> result; std::vector<wchar_t> vtxt(wcslen(src) + 1, '\0'); wchar_t* txt = &vtxt[0]; wcscpy(txt, src); wchar_t* t = wcstok(txt, del); if (wcslen(t) != 0) { result.push_back(t); } while (t != nullptr) { t = wcstok(nullptr, del); if (t != nullptr) { result.push_back(t); } } return result; }
結果出力
for (size_t i = 0; i < cret.size(); i++) { printf("[%s]",cret[i].c_str()); }
strtokで生じる問題
実験1
分割文字が連続していても思った通りに分割出来る
std::vector<std::string> cret =
split_mb("hello world characters", " ");
結果
[hello][world][characters]
実験2
此は成功する
std::vector<std::string> cret =
split_mb("C:\\test\\english folder\\contents\\", "\\");
結果
[C:][test][english folder][contents]
実験3
「表示」のように分割文字が入っている場合は、思ったような結果が得られない
std::vector<std::string> cret =
split_mb("C:\\test\\日本語表示フォルダ\\内容\\", "\\");
結果
[C:][test][日本語評[示フォルダ][内容]
C/C++ fgetsで一行読み込む
fgetsで一行取得するサンプルは多数あるのだけれど一行がバッファサイズ超えたらどうするのというサンプルがあまりなかった。というか意味をなさないのだろうけれど。
呼び出し元
int main() { char* txt = new char[1024]; FILE* fp = fopen("test.txt", "r"); bool readable = true; while(readable){ read_1_line(txt, fp);//一行読み込み printf("%s\n", txt); readable = feof(fp) == 0; } getchar(); delete[] txt; return 0; }
一行読み込み関数
関数本体
バッファサイズが小さいので大抵は一行に収まりきらず複数回fgetsが走る。そしてfgetsがnullptrを返すか、読み込んだ文字列の最後が"\n\0"という並びの時だけループを抜ける。
#include <cstring> void read_1_line(char* txt, FILE* fp) { txt[0] = '\0'; const int BUF_SIZE = 10;//バッファサイズが小さい char buffer[BUF_SIZE]; while(fgets(buffer, BUF_SIZE, fp) ){ strcat(txt, buffer); char* p = strchr(txt, '\n');//改行の削除 if (p) { *p = '\0'; break; } } }
fgetsの挙動と改行の削除
fgetsは改行までを一行と見なして読み込む。大抵は改行が最後に入るのだが入らないこともあるのでこの方法をとる。
(参考)FIO36-C. fgets() が改行文字を読み取ると仮定しない
バッファサイズが10,読み込み文字がそれぞれ以下の時のfgetsで読み込まれる内容。
| ファイル内の一行の文字 | 一回目 | 二回目 | コメント |
| 01234567 | 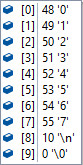 | -- | 一回で読み込める。 最後に改行 末尾は'\0' |
| 012345678 | 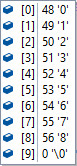 | 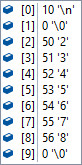 | 二回にわたって読み込む。 一回目に改行は入らない。 二回目は、一回目で読めなかった'\n'だけが読み込まれる 末尾は [1] 0 '\0' となりnull終端 |
| 0123456789 | | 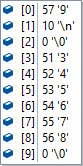 | 二回にわたって読み込む。 一回目に改行は入らない。 二回目は、一回目で読めなかった'9' '\n' 末尾は [2] 0 '\0' となりnull終端 |
C++のstring型に結合するように変更
このままでは結局引数txtの要素数に依存してしまうので、結果をどんどんstring型変数へ結合していく。
std::string read_1_line(FILE* fp) { std::string str; const int BUF_SIZE = 10; char buffer[BUF_SIZE]; while (fgets(buffer, BUF_SIZE, fp)) { char* p = strchr(buffer, '\n'); if (p) { *p = '\0'; } str += buffer; if (p)break; } return str;//コピーコスト?知らん。 }
もっともこれをやりだすとそもそもfgetsを使う必要云々という議論に発展する気がする。でもfstreamは嫌いだ。
ファイル名を自然ソートする(StrCmpLogicalW)
手順
①ファイル名を取得(wchar_t で )
②自然ソート
③必要ならcharへ変換
というステップで行います。
②StrCmpLogicalWで自然ソート (核心)
この記事の核心自然ソートです。前提として、ファイル名は
std::vector<std::wstring>
で管理されています。
StrCmpLogicalWを使う時はShlwapi.hをインクルード、shlwapi.libをリンクします。
#include <Shlwapi.h> #pragma comment(lib,"shlwapi.lib")
void sort_file_names(std::vector<std::wstring>& fnlist) { std::sort( fnlist.begin(), fnlist.end(),
//ラムダ関数 [](const std::wstring& n1, const std::wstring& n2) { return StrCmpLogicalW(n1.c_str(), n2.c_str()) < 0; } ); }
①ファイル一覧取得
ファイル名一覧を取得。StrcmpLogicalWがワイド文字専用なので、ファイル一覧の段階からワイド文字で取得します。
https://suzulang.com/win32api-get-file-list/
③必要ならcharへ変換
Win32apiでファイル一覧取得
取得用関数(_UNICODE指定時)
std::vector<std::wstring> getfiles(std::wstring path) { HANDLE hFind; WIN32_FIND_DATA win32fd; if (path.back() != L'\\') {//最後を\で終了するようにする path += L'\\'; } path += L"*.*";//ファイル一覧取得時のワイルドカード
//ここに結果を保存 std::vector<std::wstring> files_ws; hFind = FindFirstFile(path.c_str(), &win32fd); if (hFind == INVALID_HANDLE_VALUE) { return files_ws; //一覧が取得できそうにないなら終了 } do { if (win32fd.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY) {
//ディレクトリの時は win32fd.cFileName にディレクトリ名が入っている
//ここで再起などするとさらに深い階層を得られる } else { //ファイル名登録 files_ws.push_back(win32fd.cFileName); } } while (FindNextFile(hFind, &win32fd)); FindClose(hFind); return files_ws; }
各関数・および構造体は、ワイド文字用とマルチバイト文字用で分かれている
| tchar用 | マルチバイト文字用 | ワイド文字用 |
| WIN32_FIND_DATA | WIN32_FIND_DATAA | WIN32_FIND_DATAW |
| FindFirstFile | FindFirstFileA | FindFirstFileW |
| FindNextFile | FindNextFileA | FindNextFileW |
wchar_t* と char* の相互変換
プログラム
色々とやりようはあるしそこらじゅうに転がってるんですがとりあえず自分が納得するものを作ります。
std::wstring towstring(const char* c) { std::wstring tmps; if (c == nullptr) return tmps; size_t sz = strlen(c); tmps.reserve(sz);//メモリを確保し、newが走りすぎないようにする const size_t CNT_MAX = 50; char tmpc[CNT_MAX]; wchar_t tmpw[CNT_MAX]; const char* p = c; assert(p); while (*p != '\0') { int L = mblen(p, CNT_MAX);//pが指し示すマルチバイト文字のバイト数を取得 if (L <= 0) break; strncpy(tmpc, p, L);//tmpcにその一文字をコピーする tmpc[L] = '\0';
//multi byte string to wide char string mbstowcs(tmpw, tmpc, CNT_MAX);//tmpcの終端を0にしてあるので人文字だけ変換する tmps += tmpw; p += L; } return tmps; } std::string tostring(const wchar_t* c) { std::string tmps; if (c == nullptr) return tmps; size_t sz = wcslen(c); tmps.reserve(sz*2);//メモリを確保し、newが走りすぎないようにする const size_t CNT_MAX = 50; char tmpc[CNT_MAX]; wchar_t tmpw[CNT_MAX]; const wchar_t* p = c; while (*p) {
//サロゲートペアなら2文字分、違うなら1文字分だけtmpwに確保 if (IS_HIGH_SURROGATE(*p) == true) { wcsncpy(tmpw, p, 2); tmpw[2] = L'\0'; p += 2; } else { wcsncpy(tmpw, p, 1); tmpw[1] = L'\0'; p += 1; } wcstombs(tmpc, tmpw, CNT_MAX);//tmpwの内容を変換してtmpcに代入 tmps += tmpc; } return tmps; }
使う時はsetlocaleが必要です。
setlocale(LC_ALL, "");//必要 const char *c = "こんにちは"; std::wstring s = towstring(c);
IS_HIGH_SURROGATE
ここで、 IS_HIGH_SURROGATEはWindowsのマクロです。
IS_HIGH_SURROGATE macro (winnls.h) | Microsoft Docs
定義は、WinNls.hの中で、
#define IS_HIGH_SURROGATE(wch) (((wch) >= HIGH_SURROGATE_START) && ((wch) <= HIGH_SURROGATE_END))
#define IS_LOW_SURROGATE(wch) (((wch) >= LOW_SURROGATE_START) && ((wch) <= LOW_SURROGATE_END))
#define IS_SURROGATE_PAIR(hs, ls) (IS_HIGH_SURROGATE(hs) && IS_LOW_SURROGATE(ls))
こんな感じで定義されています。 なお、
#define HIGH_SURROGATE_START 0xd800 #define HIGH_SURROGATE_END 0xdbff #define LOW_SURROGATE_START 0xdc00 #define LOW_SURROGATE_END 0xdfff
mblen
用途:
stringが指す先のマルチバイト文字のバイト数を返す。
例えば、 'a' なら1 , 'あ'なら2
使い方
他所を参照(手抜き)
mblen | Programming Place Plus C言語編 標準ライブラリのリファレンス
注意
スレッドセーフではない。スレッドセーフであってほしいときはmbrlenを使う
mbstowcs
用途
マルチバイト文字列をワイド文字列に変換する。mbs to wcs。
使い方
他所を参照
mbstowcs | Programming Place Plus C言語編 標準ライブラリのリファレンス
wcstombs
ワイド 文字列を マルチバイト 文字列に変換する。 wcs to mbs。