スポンサーリンク
icuで文字列をスクリプト単位で分離
文字列をスクリプト単位に分離する。スクリプトはHarfBuzzで描画するときに使う。
#include <iostream> #include <unicode/ubrk.h> #include <unicode/ustring.h> #include <unicode/uscript.h> #include <unicode/uchar.h> #include <vector> #include <fstream> #include <algorithm> #include <Windows.h> #include <fcntl.h> #include <io.h> // 要リンク #if defined(_DEBUG) #pragma comment(lib, "icuucd.lib") #else #pragma comment(lib, "icuuc.lib") #endif struct Grapheme { int32_t start; int32_t end; };
// 文字列を書記素単位でアクセスできるようにするリストを作成 std::vector<Grapheme> createGraphemeList(const char16_t* text, const size_t length) { UErrorCode status = U_ZERO_ERROR; std::vector<Grapheme> graphemes; // イテレータ作成 UBreakIterator* bi = ubrk_open(UBRK_CHARACTER, "ja_JP", nullptr, 0, &status); if (U_FAILURE(status)) { return std::vector<Grapheme>(); // エラーが発生 } // テキストを設定 ubrk_setText(bi, (const UChar*)text, length, &status); if (U_FAILURE(status)) { ubrk_close(bi); return std::vector<Grapheme>(); // エラーが発生 } // 最初の書記素の位置を取得 int32_t start = ubrk_first(bi); int32_t end; // 書記素リストを作成 while ((end = ubrk_next(bi)) != UBRK_DONE) { graphemes.push_back(Grapheme{ start, end }); start = end; } // 終了処理 ubrk_close(bi); return graphemes; }
// 指定した書記素をutf16 からコードポイントに変換 UChar32 getCodepoint(const char16_t* text, const Grapheme& g) { UChar32 codepoint; size_t start = g.start; size_t end = g.end; U16_NEXT(text, start, end, codepoint); return codepoint; }
// 各文字ごとにスクリプトを特定 std::vector< std::pair<size_t, UScriptCode> > createScriptList(const char16_t* text, const std::vector<Grapheme>& glist) { std::vector< std::pair<size_t, UScriptCode> > scliptslice; UScriptCode latest; UErrorCode err; UChar32 codepoint; UScriptCode script; for (size_t i = 0; i < glist.size(); i++) { codepoint = getCodepoint(text, glist[i]); script = uscript_getScript(codepoint, &err); if (U_SUCCESS(err)) { latest = script; } else { latest = USCRIPT_UNKNOWN; } scliptslice.push_back({ i, latest }); } return scliptslice; }
struct ScriptSlice { size_t grapheme_start; size_t grapheme_end; UScriptCode script; };
// 一文字ごとに設定されているスクリプトを元に、同じスクリプトが連続している部分をひとまとめにする std::vector<ScriptSlice> ScriptListShrink(const std::vector< std::pair<size_t, UScriptCode> >& ss) { std::vector<ScriptSlice> slist; UScriptCode script = ss[0].second; slist.push_back({ ss[0].first, ss[0].first, ss[0].second}); for (size_t i = 1; i < ss.size(); i++) { if (ss[i].second != slist.back().script) { slist.back().grapheme_end = ss[i].first-1; slist.push_back({ ss[i].first,ss[i].first, ss[i].second }); } } slist.back().grapheme_end = ss.back().first; return slist; }
int main() { // 日本語ロケール std::locale::global(std::locale("japanese")); std::u16string u16str = u"あいうイロハホヘト你好😁👩👨👦👧ÄɪʊabcQué"; // 書記素リスト作成 std::vector<Grapheme> glist = createGraphemeList(u16str.data(), u16str.length()); // 書記素リストを元にスクリプトリストを作成 std::vector< std::pair<size_t, UScriptCode> > slist = createScriptList(u16str.data(), glist); // スクリプトリストを元に、同じスクリプトが連続している部分をひとまとめにする std::vector<ScriptSlice> ss = ScriptListShrink(slist); // 同じスクリプト単位で表示 for (size_t i = 0; i < ss.size(); i++) { size_t u16start = glist[ss[i].grapheme_start].start; size_t u16end = glist[ss[i].grapheme_end].end; size_t length = u16end - u16start; std::u16string u16wstr(u16str.data() + u16start, length); std::wcout << L"[" << ss[i].script << L"] "; WriteConsoleW(GetStdHandle(STD_OUTPUT_HANDLE), u16wstr.c_str(), length, nullptr, nullptr); WriteConsoleW(GetStdHandle(STD_OUTPUT_HANDLE), L"\n", 2, nullptr, nullptr); } return 0; }
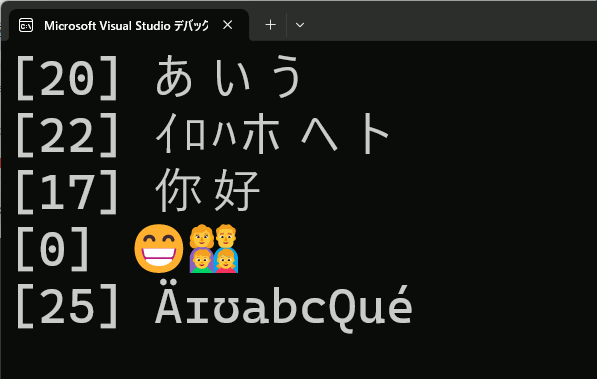
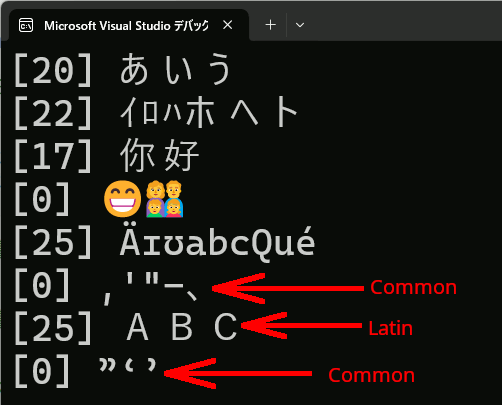
問題
、や全角英数など文字によってはイメージと違うことがある。
std::u16string u16str = u"あいうイロハホヘト你好😁👩👨👦👧ÄɪʊabcQué,'\"-、ABC”‘’"
この記事のトラックバックURL: