スポンサーリンク
HarfBuzzでスクリプト(用字)を取得
ICUライブラリの uscript_getScript を使用すれば用字を取得できる。が、どうやらHarfBuzzのhb_unicode_script関数を使用しても可能らしい。
#include <iostream> #include <vector> #include <string> #include <hb.h> #include <hb-ft.h> #ifdef _DEBUG #pragma comment(lib,"harfbuzz.lib") #else #pragma comment(lib,"harfbuzz.lib") #endif #pragma warning(disable:4996)
// UTF-32の文字列の各文字のスクリプトを取得する関数 std::vector<hb_script_t> get_scripts_from_utf32(const std::u32string& text, hb_unicode_funcs_t* ufuncs) { std::vector<hb_script_t> scripts; // 出力用 for (char32_t ch : text) { hb_script_t script = hb_unicode_script(ufuncs, ch); // スクリプトの取得 scripts.push_back(script); } return scripts; }
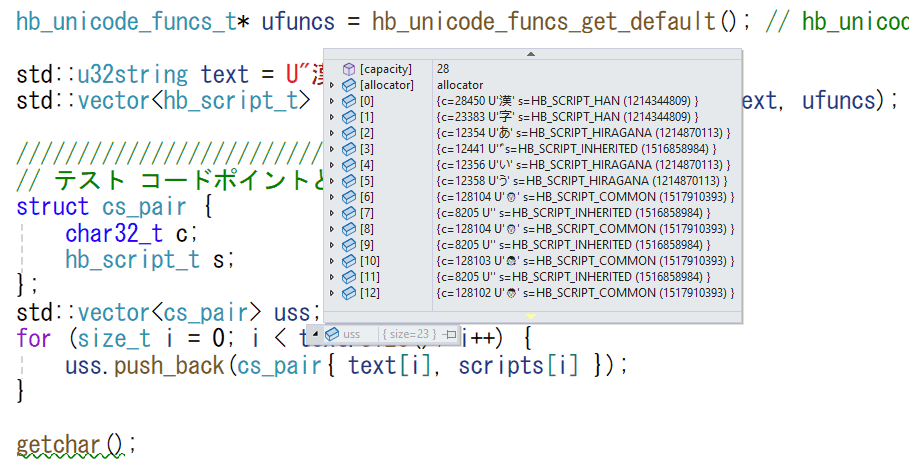
int main() { ////////////////////////////////////////////////////// // HarfBuzzのUnicode関数の取得 hb_unicode_funcs_t* ufuncs = hb_unicode_funcs_get_default(); // hb_unicode_scriptに渡す構造体(解放不要) std::u32string text = U"漢字あ゙いう👨👨👧👦àbâáăã"; std::vector<hb_script_t> scripts = get_scripts_from_utf32(text, ufuncs); //////////////////////////////////////////// // テスト コードポイントとスクリプトのペアを作成 struct cs_pair { char32_t c; hb_script_t s; }; std::vector<cs_pair> uss; for (size_t i = 0; i < text.size(); i++) { uss.push_back(cs_pair{ text[i], scripts[i] }); } getchar(); }
デバッグモードで確認すると、文字に対応した用字が得られているのがわかる
この記事のトラックバックURL: