スポンサーリンク
CUDAで複数の.cuファイルを使用する
CUDAのヘッダファイルの拡張子がcuhだと知り、では関数宣言を.cuhに書き、定義を.cuに書けば分割コンパイル的(?)なことができるのではないかと思ったのだが、リンクエラーが出たので対処法を調べた。
ptxas fatal : Unresolved extern function '_Z13color_inversePhii'
color_inverse関数(自作関数 , .cuhで宣言、.cuに定義)が見つからない
今回使ったのは以下。
・mytest.h ... CPU側から呼び出すときにincludeするヘッダファイル。
・mytest.cu ... CPU側から呼び出される処理。__global__関数も入っている。
・function.cu ... __device__関数のみが入っている。mytest.cuから呼び出される
・function.cuh ... function.cuの関数の宣言が入る。
CUDA側
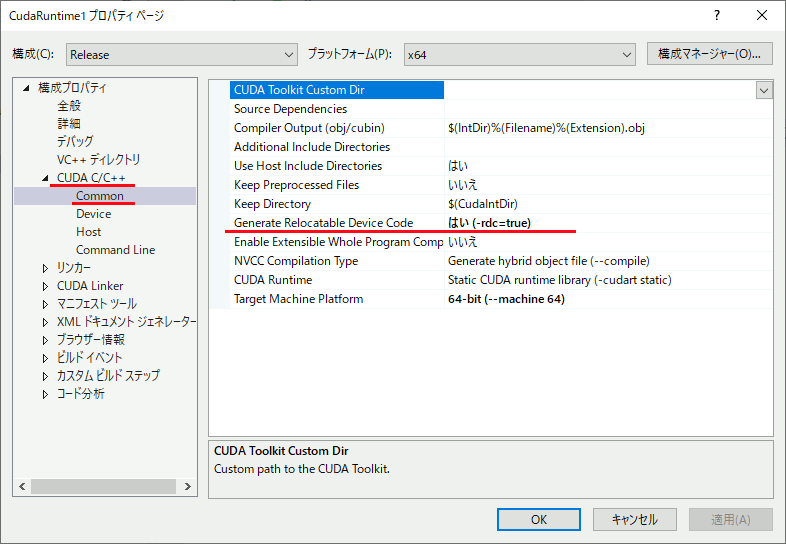
設定
CUDA C/C++ → Common → Generate Relocatable Device Codeを はい (-rdc=true) に設定
mytest.h
#ifdef __DLL_EXPORT_DO #define DLL_PORT extern "C" _declspec(dllexport) #else #define DLL_PORT extern "C" _declspec(dllimport) #endif struct data_t { int width; int height; unsigned char* rgbdata; }; DLL_PORT void func_inverse(data_t* data);
mytest.cu
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> #include "mytest.h" // cudaのヘッダファイルは.cuhらしい #include "function.cuh" struct gpudata { int width; int height; unsigned char* c; }; __global__ void thread_inverse(gpudata data) { //このスレッドが担当する画素の位置を二次元座標で求める size_t xpos = blockIdx.x * blockDim.x + threadIdx.x; size_t ypos = blockIdx.y * blockDim.y + threadIdx.y; if (xpos < data.width && ypos < data.height) { size_t pos = (ypos * data.width + xpos) * 3; unsigned char* c = data.c + pos; // この関数はfunction.cuで定義されている color_inverse(c, xpos, ypos); } } void func_inverse(data_t* data) { // 16*16 == 256 < 512 int blockw = 16; int blockh = 16; dim3 block(blockw, blockh); int gridw = data->width / blockw + 1; int gridh = data->height / blockh + 1; dim3 grid(gridw,gridh); unsigned char* c_gpu; cudaMalloc((void**)&c_gpu, data->width*data->height*3);//GPU側にメモリを確保 cudaMemcpy( c_gpu, data->rgbdata, data->width* data->height*3, cudaMemcpyHostToDevice);//GPU側から実行結果を取得 gpudata gpud; gpud.width = data->width; gpud.height = data->height; gpud.c = c_gpu; thread_inverse<<<grid,block>>> (gpud);//GPU側の関数を呼出 cudaMemcpy( data->rgbdata, c_gpu, data->width * data->height * 3, cudaMemcpyDeviceToHost);//GPU側から実行結果を取得 cudaFree(c_gpu);//GPU側のメモリを解放 }
function.cuh
#include "cuda_runtime.h" __device__ void color_inverse(unsigned char* c, int width, int height);
function.cu
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include "function.cuh" __device__ void color_inverse(unsigned char* c, int width, int height) { c[0] = 255 - c[0]; c[1] = 255 - c[1]; c[2] = 255 - c[2]; }
C++側
#include <iostream> #pragma warning(disable:4996) #include "../CudaRuntime1/mytest.h" #pragma comment(lib,"CudaRuntime1.lib") void pnmP3_Write(const char* const fname, const int vmax, const int width, const int height, const unsigned char* const p);
int main() { data_t dat; dat.width = 100; dat.height = 50; unsigned char *c = new unsigned char[dat.width * dat.height * 3]; for (size_t i = 0; i < dat.width * dat.height; i++) { c[i * 3 + 0] = 0; c[i * 3 + 1] = 0; c[i * 3 + 2] = 255; } dat.rgbdata = c; func_inverse(&dat); pnmP3_Write("test.ppm", 255, dat.width, dat.height, dat.rgbdata); }
///////////////////////////////////////////// //画像ファイル書き出し///////////////////////// //! @brief PPM(RGB各1byte,カラー,テキスト)を書き込む //! @param [in] fname ファイル名 //! @param [in] vmax 全てのRGBの中の最大値 //! @param [in] width 画像の幅 //! @param [in] height 画像の高さ //! @param [in] p 画像のメモリへのアドレス //! @details RGBRGBRGB....のメモリを渡すと、RGBテキストでファイル名fnameで書き込む void pnmP3_Write(const char* const fname, const int vmax, const int width, const int height, const unsigned char* const p) { // PPM ASCII FILE* fp = fopen(fname, "wb"); fprintf(fp, "P3\n%d %d\n%d\n", width, height, vmax); size_t k = 0; for (size_t i = 0; i < (size_t)height; i++) { for (size_t j = 0; j < (size_t)width; j++) { fprintf(fp, "%d %d %d ", p[k * 3 + 0], p[k * 3 + 1], p[k * 3 + 2]); k++; } fprintf(fp, "\n"); } fclose(fp); }
この記事のトラックバックURL: