スポンサーリンク
OptiX 9.0を試す(2)optixRaycastingのプロジェクトに必要なファイルを確認
optixRaycastingのプロジェクトにどのファイルが必要かを確認する
ソースコードの場所:
C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\SDK\optixRaycasting\
に、以下のファイルが存在
- optixRaycasting.cpp
- optixRaycasting.cu
- optixRaycasting.h
- optixRaycastingKernels.cu
- optixRaycastingKernels.h
.cu.obj / dlink.obj / .cu.optixir の作成
プロジェクトの作成の前に、nvccで以下を生成しておく。
cl.exeも呼び出されるので、x64 Native Tools Command Prompt等で実行する。
.cu.optixir
nvcc optixRaycasting.cu -o optixRaycasting_generated_optixRaycasting.cu.optixir -arch compute_50 -lineinfo -use_fast_math -optix-ir -rdc true -D__x86_64 -I"C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\include" -I"C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\SDK"
.cu.obj の作成
本体のC++プロジェクトがMTかMDかでビルドオプションを変える
MT
nvcc optixRaycastingKernels.cu -c -o optixRaycasting_generated_optixRaycastingKernels.cu.obj -arch compute_50 -lineinfo -use_fast_math -rdc true -D__x86_64 -I"C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\include" -I"C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\SDK"
MD
nvcc optixRaycastingKernels.cu -c -o optixRaycasting_generated_optixRaycastingKernels.cu.obj -arch compute_50 -lineinfo -use_fast_math -rdc true -D__x86_64 -Xcompiler "/MD" -I"C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\include" -I"C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\SDK"
dlink.obj (デバイスリンク)
nvcc -dlink optixRaycasting_generated_optixRaycastingKernels.cu.obj -o optixRaycasting_generated_optixRaycastingKernels_dlink.obj -arch compute_50 -Xcompiler "/MD" -L"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\lib\x64" -lcudart_static
C++プロジェクト
- optixRaycasting.cpp
- optixRaycasting.h
- optixRaycastingKernels.h
で、VC++で、C++プロジェクトを作成。
ぱっと見いらないものなどを消して、依存関係やらを整頓する。
・サンプルをビルドしたディレクトリ内にある sutil_7_sdk.lib が必要。
・gladはこの段階では取り除けなかった。
・sutil::loadSceneがモデルの他にシーン情報も設定している
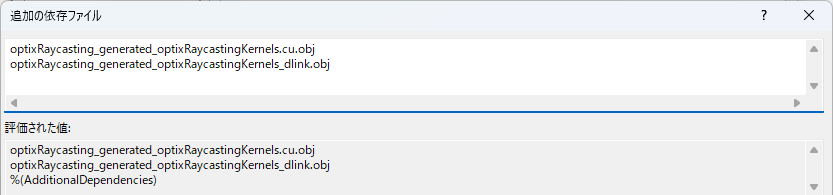
・optixRaycasting_generated_optixRaycastingKernels.cu.obj optixRaycasting_generated_optixRaycastingKernels_dlink.obj をリンカー → 入力 → 追加の依存ファイルに追記しておく
/* * SPDX-FileCopyrightText: Copyright (c) 2019 - 2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved. * SPDX-License-Identifier: BSD-3-Clause * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions are met: * * 1. Redistributions of source code must retain the above copyright notice, this * list of conditions and the following disclaimer. * * 2. Redistributions in binary form must reproduce the above copyright notice, * this list of conditions and the following disclaimer in the documentation * and/or other materials provided with the distribution. * * 3. Neither the name of the copyright holder nor the names of its * contributors may be used to endorse or promote products derived from * this software without specific prior written permission. * * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE * DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE * FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR * SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE * OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. */ #include <cuda_runtime.h> #include <optix.h> #include <optix_function_table_definition.h> #include <optix_stack_size.h> #include <optix_stubs.h> /* // Include ディレクトリ C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\include C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\SDK\cuda C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\SDK C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\include C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\SDK\support\imgui\.. */ /* // nvccでビルドして作成する各種関連ファイル: optixRaycasting_generated_optixRaycastingKernels.cu.obj optixRaycasting_generated_optixRaycastingKernels_dlink.obj */ /* プリプロセッサ _USE_MATH_DEFINES NOMINMAX GLAD_GLAPI_EXPORT */ // D:\tmp\optixbuild ここでインクルードしなくてもよい //#include <sampleConfig.h> #include <fstream> // getInputDataの代わりにifstreamを使う #include "cuda/whitted.h" #include <sutil/CUDAOutputBuffer.h> #include <sutil/Matrix.h> #include <sutil/Record.h> #include <sutil/Scene.h> #include <sutil/sutil.h> #include "optixRaycasting.h" #include "optixRaycastingKernels.h" #include <iomanip> #pragma comment(lib, "D:\\tmp\\optixbuild\\lib\\Release\\glad.lib") #pragma comment(lib, "D:\\tmp\\optixbuild\\lib\\Release\\sutil_7_sdk.lib") #pragma comment(lib, "C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v12.8\\lib\\x64\\cudart_static.lib") #pragma comment(lib, "C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v12.8\\lib\\x64\\cudadevrt.lib") struct RaycastingState { int width = 0; int height = 0; OptixDeviceContext context = 0; sutil::Scene scene = {}; OptixPipelineCompileOptions pipeline_compile_options = {}; OptixModule ptx_module = 0; OptixPipeline pipeline_1 = 0; OptixPipeline pipeline_2 = 0; OptixProgramGroup raygen_prog_group = 0; OptixProgramGroup miss_prog_group = 0; OptixProgramGroup hit_prog_group = 0; Params params = {}; Params params_translated = {}; OptixShaderBindingTable sbt = {}; sutil::Texture mask = {}; }; typedef sutil::Record<whitted::HitGroupData> HitGroupRecord; void createModule( RaycastingState& state ) { OptixModuleCompileOptions module_compile_options = {}; #if OPTIX_DEBUG_DEVICE_CODE module_compile_options.optLevel = OPTIX_COMPILE_OPTIMIZATION_LEVEL_0; module_compile_options.debugLevel = OPTIX_COMPILE_DEBUG_LEVEL_FULL; #else module_compile_options.optLevel = OPTIX_COMPILE_OPTIMIZATION_DEFAULT; module_compile_options.debugLevel = OPTIX_COMPILE_DEBUG_LEVEL_MINIMAL; #endif state.pipeline_compile_options.usesMotionBlur = false; state.pipeline_compile_options.traversableGraphFlags = OPTIX_TRAVERSABLE_GRAPH_FLAG_ALLOW_SINGLE_LEVEL_INSTANCING; state.pipeline_compile_options.numPayloadValues = 4; state.pipeline_compile_options.numAttributeValues = 2; state.pipeline_compile_options.exceptionFlags = OPTIX_EXCEPTION_FLAG_NONE; state.pipeline_compile_options.pipelineLaunchParamsVariableName = "params"; size_t inputSize = 0; // 使いにくいので書き換え #if 0 const char* input = sutil::getInputData( OPTIX_SAMPLE_NAME, OPTIX_SAMPLE_DIR, "optixRaycasting.cu", inputSize ); #else
std::string filepath = "optixRaycasting_generated_optixRaycasting.cu.optixir"; std::ifstream file(filepath, std::ios::binary | std::ios::ate); if (!file) throw std::runtime_error("Failed to open file: " + filepath); std::streamsize size = file.tellg(); // ファイルサイズ file.seekg(0, std::ios::beg); // 先頭へ移動 std::vector<char> buffer; buffer.resize(size); if (!file.read(buffer.data(), size)) throw std::runtime_error("Failed to read file: " + filepath); const char* input = buffer.data(); inputSize = size;
#endif // optixModuleCreateに.optixirを与える OPTIX_CHECK_LOG( optixModuleCreate( state.context, &module_compile_options, &state.pipeline_compile_options, input, inputSize, LOG, &LOG_SIZE, &state.ptx_module ) ); } void createProgramGroups( RaycastingState& state ) { OptixProgramGroupOptions program_group_options = {}; OptixProgramGroupDesc raygen_prog_group_desc = {}; raygen_prog_group_desc.kind = OPTIX_PROGRAM_GROUP_KIND_RAYGEN; raygen_prog_group_desc.raygen.module = state.ptx_module; raygen_prog_group_desc.raygen.entryFunctionName = "__raygen__from_buffer"; OPTIX_CHECK_LOG( optixProgramGroupCreate( state.context, &raygen_prog_group_desc, 1, // num program groups &program_group_options, LOG, &LOG_SIZE, &state.raygen_prog_group ) ); OptixProgramGroupDesc miss_prog_group_desc = {}; miss_prog_group_desc.kind = OPTIX_PROGRAM_GROUP_KIND_MISS; miss_prog_group_desc.miss.module = state.ptx_module; miss_prog_group_desc.miss.entryFunctionName = "__miss__buffer_miss"; OPTIX_CHECK_LOG( optixProgramGroupCreate( state.context, &miss_prog_group_desc, 1, // num program groups &program_group_options, LOG, &LOG_SIZE, &state.miss_prog_group ) ); OptixProgramGroupDesc hit_prog_group_desc = {}; hit_prog_group_desc.kind = OPTIX_PROGRAM_GROUP_KIND_HITGROUP; hit_prog_group_desc.hitgroup.moduleAH = state.ptx_module; hit_prog_group_desc.hitgroup.entryFunctionNameAH = "__anyhit__texture_mask"; hit_prog_group_desc.hitgroup.moduleCH = state.ptx_module; hit_prog_group_desc.hitgroup.entryFunctionNameCH = "__closesthit__buffer_hit"; OPTIX_CHECK_LOG( optixProgramGroupCreate( state.context, &hit_prog_group_desc, 1, // num program groups &program_group_options, LOG, &LOG_SIZE, &state.hit_prog_group ) ); } void createPipelines( RaycastingState& state ) { const uint32_t max_trace_depth = 1; OptixProgramGroup program_groups[3] = {state.raygen_prog_group, state.miss_prog_group, state.hit_prog_group}; OptixPipelineLinkOptions pipeline_link_options = {}; pipeline_link_options.maxTraceDepth = max_trace_depth; OPTIX_CHECK_LOG( optixPipelineCreate( state.context, &state.pipeline_compile_options, &pipeline_link_options, program_groups, sizeof( program_groups ) / sizeof( program_groups[0] ), LOG, &LOG_SIZE, &state.pipeline_1 ) ); OPTIX_CHECK_LOG( optixPipelineCreate( state.context, &state.pipeline_compile_options, &pipeline_link_options, program_groups, sizeof( program_groups ) / sizeof( program_groups[0] ), LOG, &LOG_SIZE, &state.pipeline_2 ) ); OptixStackSizes stack_sizes_1 = {}; OptixStackSizes stack_sizes_2 = {}; for( auto& prog_group : program_groups ) { OPTIX_CHECK( optixUtilAccumulateStackSizes( prog_group, &stack_sizes_1, state.pipeline_1 ) ); OPTIX_CHECK( optixUtilAccumulateStackSizes( prog_group, &stack_sizes_2, state.pipeline_2 ) ); } uint32_t direct_callable_stack_size_from_traversal; uint32_t direct_callable_stack_size_from_state; uint32_t continuation_stack_size; OPTIX_CHECK( optixUtilComputeStackSizes( &stack_sizes_1, max_trace_depth, 0, // maxCCDepth 0, // maxDCDEpth &direct_callable_stack_size_from_traversal, &direct_callable_stack_size_from_state, &continuation_stack_size ) ); OPTIX_CHECK( optixPipelineSetStackSize( state.pipeline_1, direct_callable_stack_size_from_traversal, direct_callable_stack_size_from_state, continuation_stack_size, 2 // maxTraversableDepth ) ); OPTIX_CHECK( optixUtilComputeStackSizes( &stack_sizes_2, max_trace_depth, 0, // maxCCDepth 0, // maxDCDEpth &direct_callable_stack_size_from_traversal, &direct_callable_stack_size_from_state, &continuation_stack_size ) ); OPTIX_CHECK( optixPipelineSetStackSize( state.pipeline_2, direct_callable_stack_size_from_traversal, direct_callable_stack_size_from_state, continuation_stack_size, 2 // maxTraversableDepth ) ); } void createSBT( RaycastingState& state ) { // raygen CUdeviceptr d_raygen_record = 0; const size_t raygen_record_size = sizeof( sutil::EmptyRecord ); CUDA_CHECK( cudaMalloc( reinterpret_cast<void**>( &d_raygen_record ), raygen_record_size ) ); sutil::EmptyRecord rg_record; OPTIX_CHECK( optixSbtRecordPackHeader( state.raygen_prog_group, &rg_record ) ); CUDA_CHECK( cudaMemcpy( reinterpret_cast<void*>( d_raygen_record ), &rg_record, raygen_record_size, cudaMemcpyHostToDevice ) ); // miss CUdeviceptr d_miss_record = 0; const size_t miss_record_size = sizeof( sutil::EmptyRecord ); CUDA_CHECK( cudaMalloc( reinterpret_cast<void**>( &d_miss_record ), miss_record_size ) ); sutil::EmptyRecord ms_record; OPTIX_CHECK( optixSbtRecordPackHeader( state.miss_prog_group, &ms_record ) ); CUDA_CHECK( cudaMemcpy( reinterpret_cast<void*>( d_miss_record ), &ms_record, miss_record_size, cudaMemcpyHostToDevice ) ); // hit group std::vector<HitGroupRecord> hitgroup_records; for( const auto& mesh : state.scene.meshes() ) { for( size_t i = 0; i < mesh->material_idx.size(); ++i ) { HitGroupRecord rec = {}; OPTIX_CHECK( optixSbtRecordPackHeader( state.hit_prog_group, &rec ) ); GeometryData::TriangleMesh triangle_mesh = {}; triangle_mesh.positions = mesh->positions[i]; triangle_mesh.normals = mesh->normals[i]; for( size_t j = 0; j < GeometryData::num_texcoords; ++j ) triangle_mesh.texcoords[j] = mesh->texcoords[j][i]; triangle_mesh.indices = mesh->indices[i]; rec.data.geometry_data.setTriangleMesh( triangle_mesh ); rec.data.material_data = state.scene.materials()[mesh->material_idx[i]]; hitgroup_records.push_back( rec ); } } CUdeviceptr d_hitgroup_record = 0; const size_t hitgroup_record_size = sizeof( HitGroupRecord ); CUDA_CHECK( cudaMalloc( reinterpret_cast<void**>( &d_hitgroup_record ), hitgroup_record_size * hitgroup_records.size() ) ); CUDA_CHECK( cudaMemcpy( reinterpret_cast<void*>( d_hitgroup_record ), hitgroup_records.data(), hitgroup_record_size * hitgroup_records.size(), cudaMemcpyHostToDevice ) ); state.sbt.raygenRecord = d_raygen_record; state.sbt.missRecordBase = d_miss_record; state.sbt.missRecordStrideInBytes = static_cast<uint32_t>( miss_record_size ); state.sbt.missRecordCount = RAY_TYPE_COUNT; state.sbt.hitgroupRecordBase = d_hitgroup_record; state.sbt.hitgroupRecordStrideInBytes = static_cast<uint32_t>( hitgroup_record_size ); state.sbt.hitgroupRecordCount = static_cast<int>( hitgroup_records.size() ); } void bufferRays( RaycastingState& state ) { // Create CUDA buffers for rays and hits sutil::Aabb aabb = state.scene.aabb(); aabb.invalidate(); for( const auto& instance : state.scene.instances() ) aabb.include( instance->world_aabb ); const float3 bbox_span = aabb.extent(); state.height = static_cast<int>( state.width * bbox_span.y / bbox_span.x ); Ray* rays_d = 0; Ray* translated_rays_d = 0; size_t rays_size_in_bytes = sizeof( Ray ) * state.width * state.height; CUDA_CHECK( cudaMalloc( &rays_d, rays_size_in_bytes ) ); CUDA_CHECK( cudaMalloc( &translated_rays_d, rays_size_in_bytes ) ); createRaysOrthoOnDevice( rays_d, state.width, state.height, aabb.m_min, aabb.m_max, 0.05f ); CUDA_CHECK( cudaGetLastError() ); CUDA_CHECK( cudaMemcpy( translated_rays_d, rays_d, rays_size_in_bytes, cudaMemcpyDeviceToDevice ) ); translateRaysOnDevice( translated_rays_d, state.width * state.height, bbox_span * make_float3( 0.2f, 0, 0 ) ); CUDA_CHECK( cudaGetLastError() ); Hit* hits_d = 0; Hit* translated_hits_d = 0; size_t hits_size_in_bytes = sizeof( Hit ) * state.width * state.height; CUDA_CHECK( cudaMalloc( &hits_d, hits_size_in_bytes ) ); CUDA_CHECK( cudaMalloc( &translated_hits_d, hits_size_in_bytes ) ); state.params = {state.scene.traversableHandle(), rays_d, hits_d}; state.params_translated = {state.scene.traversableHandle(), translated_rays_d, translated_hits_d}; } void launch( RaycastingState& state ) { CUstream stream_1 = 0; CUstream stream_2 = 0; CUDA_CHECK( cudaStreamCreate( &stream_1 ) ); CUDA_CHECK( cudaStreamCreate( &stream_2 ) ); Params* d_params = 0; Params* d_params_translated = 0; CUDA_CHECK( cudaMalloc( reinterpret_cast<void**>( &d_params ), sizeof( Params ) ) ); CUDA_CHECK( cudaMemcpyAsync( reinterpret_cast<void*>( d_params ), &state.params, sizeof( Params ), cudaMemcpyHostToDevice, stream_1 ) ); OPTIX_CHECK( optixLaunch( state.pipeline_1, stream_1, reinterpret_cast<CUdeviceptr>( d_params ), sizeof( Params ), &state.sbt, state.width, state.height, 1 ) ); // Translated CUDA_CHECK( cudaMalloc( reinterpret_cast<void**>( &d_params_translated ), sizeof( Params ) ) ); CUDA_CHECK( cudaMemcpyAsync( reinterpret_cast<void*>( d_params_translated ), &state.params_translated, sizeof( Params ), cudaMemcpyHostToDevice, stream_2 ) ); OPTIX_CHECK( optixLaunch( state.pipeline_2, stream_2, reinterpret_cast<CUdeviceptr>( d_params_translated ), sizeof( Params ), &state.sbt, state.width, state.height, 1 ) ); CUDA_SYNC_CHECK(); CUDA_CHECK( cudaFree( reinterpret_cast<void*>( d_params ) ) ); CUDA_CHECK( cudaFree( reinterpret_cast<void*>( d_params_translated ) ) ); } void shadeHits( RaycastingState& state, const std::string& outfile ) { sutil::CUDAOutputBufferType output_buffer_type = sutil::CUDAOutputBufferType::CUDA_DEVICE; sutil::CUDAOutputBuffer<float3> output_buffer( output_buffer_type, state.width, state.height ); sutil::ImageBuffer buffer; buffer.width = state.width; buffer.height = state.height; buffer.pixel_format = sutil::BufferImageFormat::FLOAT3; // Original shadeHitsOnDevice( output_buffer.map(), state.width * state.height, state.params.hits ); CUDA_CHECK( cudaGetLastError() ); output_buffer.unmap(); std::string ppmfile = outfile + ".ppm"; buffer.data = output_buffer.getHostPointer(); sutil::saveImage( ppmfile.c_str(), buffer, false ); std::cerr << "Wrote image to " << ppmfile << std::endl; // Translated shadeHitsOnDevice( output_buffer.map(), state.width * state.height, state.params_translated.hits ); CUDA_CHECK( cudaGetLastError() ); output_buffer.unmap(); ppmfile = outfile + "_translated.ppm"; buffer.data = output_buffer.getHostPointer(); sutil::saveImage( ppmfile.c_str(), buffer, false ); std::cerr << "Wrote translated image to " << ppmfile << std::endl; } void cleanup( RaycastingState& state ) { OPTIX_CHECK( optixPipelineDestroy( state.pipeline_1 ) ); OPTIX_CHECK( optixPipelineDestroy( state.pipeline_2 ) ); OPTIX_CHECK( optixProgramGroupDestroy( state.raygen_prog_group ) ); OPTIX_CHECK( optixProgramGroupDestroy( state.miss_prog_group ) ); OPTIX_CHECK( optixProgramGroupDestroy( state.hit_prog_group ) ); OPTIX_CHECK( optixModuleDestroy( state.ptx_module ) ); CUDA_CHECK( cudaFree( reinterpret_cast<void*>( state.params.rays ) ) ); CUDA_CHECK( cudaFree( reinterpret_cast<void*>( state.params.hits ) ) ); CUDA_CHECK( cudaFree( reinterpret_cast<void*>( state.params_translated.rays ) ) ); CUDA_CHECK( cudaFree( reinterpret_cast<void*>( state.params_translated.hits ) ) ); CUDA_CHECK( cudaFree( reinterpret_cast<void*>( state.sbt.raygenRecord ) ) ); CUDA_CHECK( cudaFree( reinterpret_cast<void*>( state.sbt.missRecordBase ) ) ); CUDA_CHECK( cudaFree( reinterpret_cast<void*>( state.sbt.hitgroupRecordBase ) ) ); CUDA_CHECK( cudaDestroyTextureObject( state.mask.texture ) ); CUDA_CHECK( cudaFreeArray( state.mask.array ) ); } int main( int argc, char** argv ) { std::string infile, outfile; RaycastingState state; state.width = 640; // .gltfはモデルとシーン情報を含む // データの場所: // C:\ProgramData\NVIDIA Corporation\OptiX SDK 9.0.0\SDK\data infile = sutil::sampleDataFilePath("Duck/DuckHole.gltf"); outfile = "output"; try { sutil::loadScene( infile.c_str(), state.scene ); state.scene.createContext(); state.scene.buildMeshAccels(); state.scene.buildInstanceAccel( RAY_TYPE_COUNT ); state.context = state.scene.context(); OPTIX_CHECK( optixInit() ); // Need to initialize function table createModule( state ); createProgramGroups( state ); createPipelines( state ); createSBT( state ); bufferRays( state ); launch( state ); shadeHits( state, outfile ); cleanup( state ); } catch( std::exception& e ) { std::cerr << "Caught exception: " << e.what() << std::endl; return 1; } return 0; }
この記事のトラックバックURL: